
We’re delighted to announce Screaming Frog SEO Spider version 21.0, codenamed internally as ‘towbar’.
This update contains new features and improvements based upon user feedback and as ever, a little internal steer.
So, let’s take a look at what’s new.
1) Direct AI API Integration
In our version 20.0 release we introduced the ability to connect to LLMs and query against crawl data via custom JavaScript snippets.
In this update, you’re now able to directly connect to OpenAI, Gemini and Ollama APIs and set up custom prompts with crawl data.
You can configure up to 100 custom AI prompts via ‘Config > API Access > AI’.
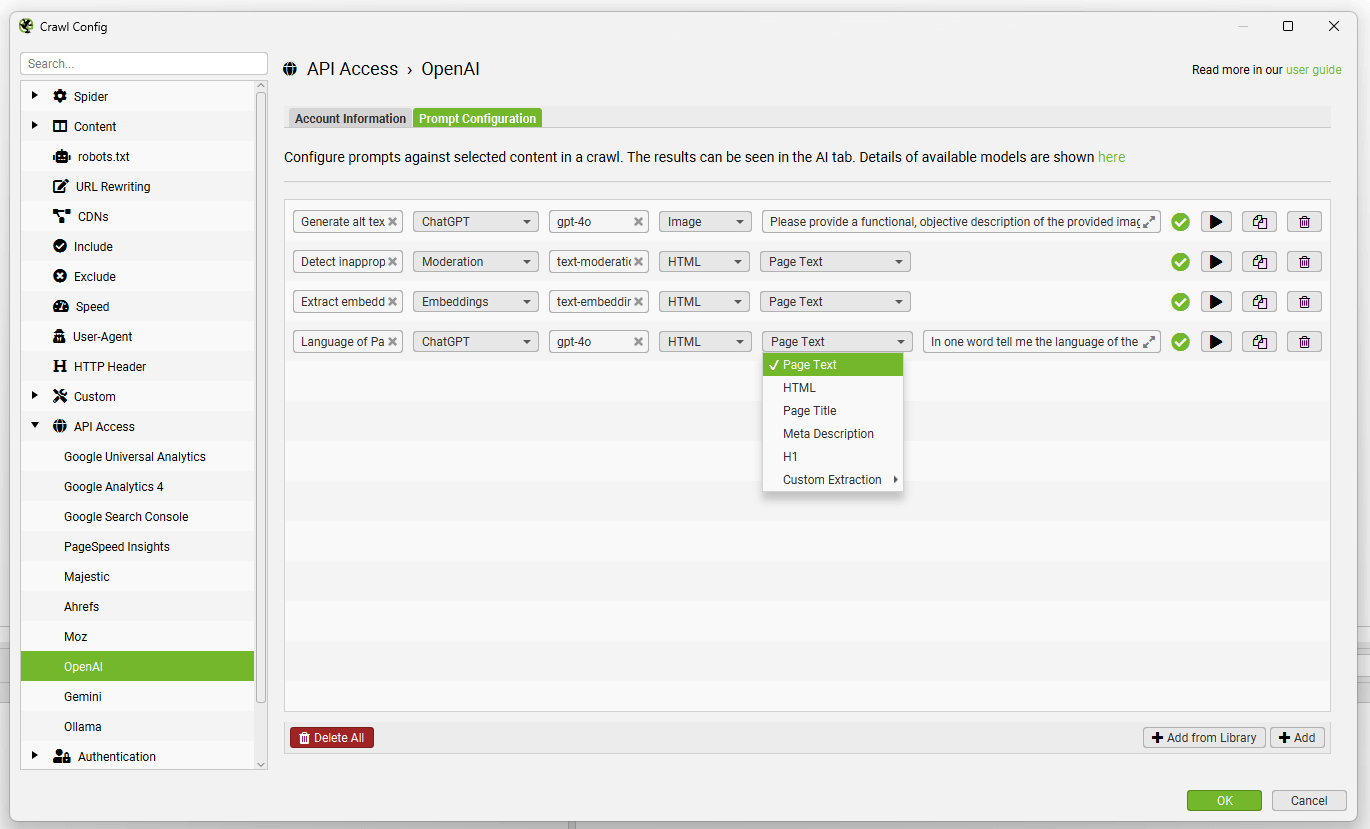
You’re able to select the category of model, the AI model used, content type and data to be used for the prompt such as body text, HTML, or a custom extraction, as well as write your custom prompt.
The SEO Spider will auto-control the throttling of each model and data will appear in the new AI tab (and Internal tab, against your usual crawl data).
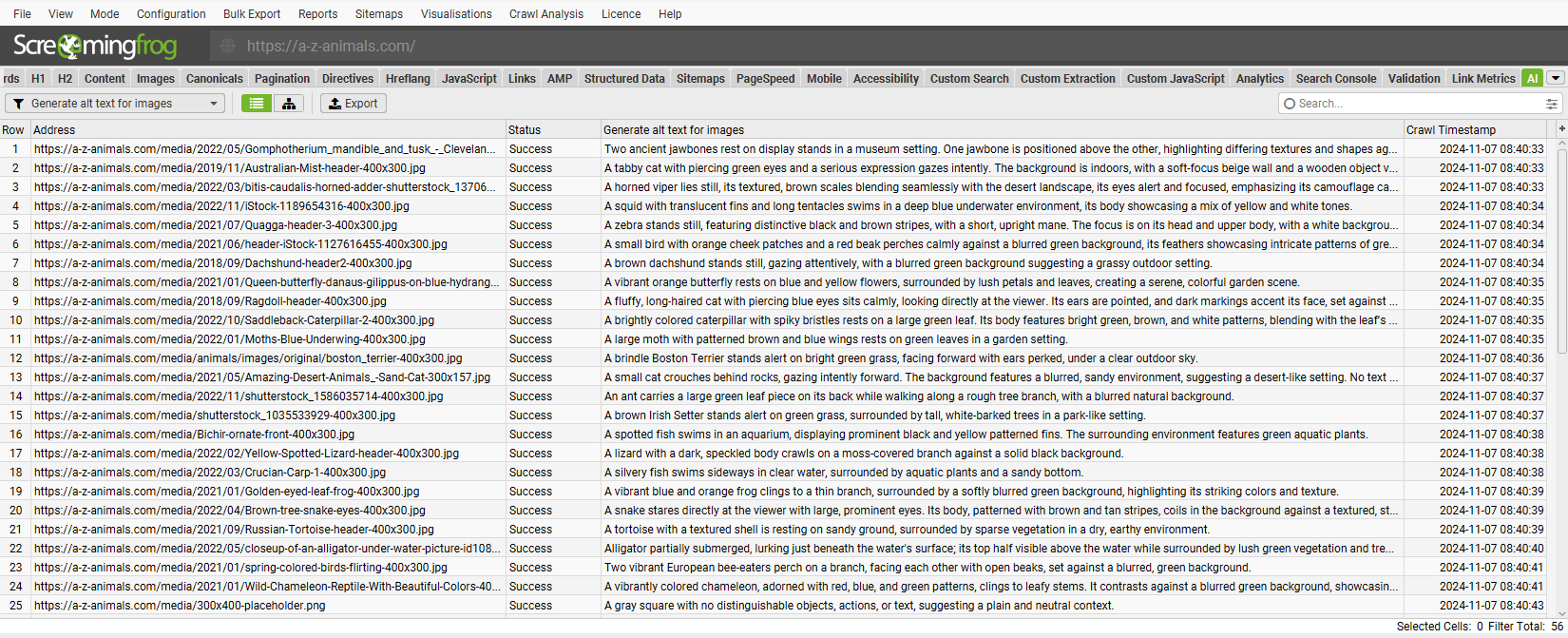
In a similar way as custom JS snippets, this can allow you to create alt text at scale, understand the language of a page, detect inappropriate content, extract embeddings and more.
The ‘Add from Library’ function includes half a dozen prompts for inspiration, but you can add and customise your own.
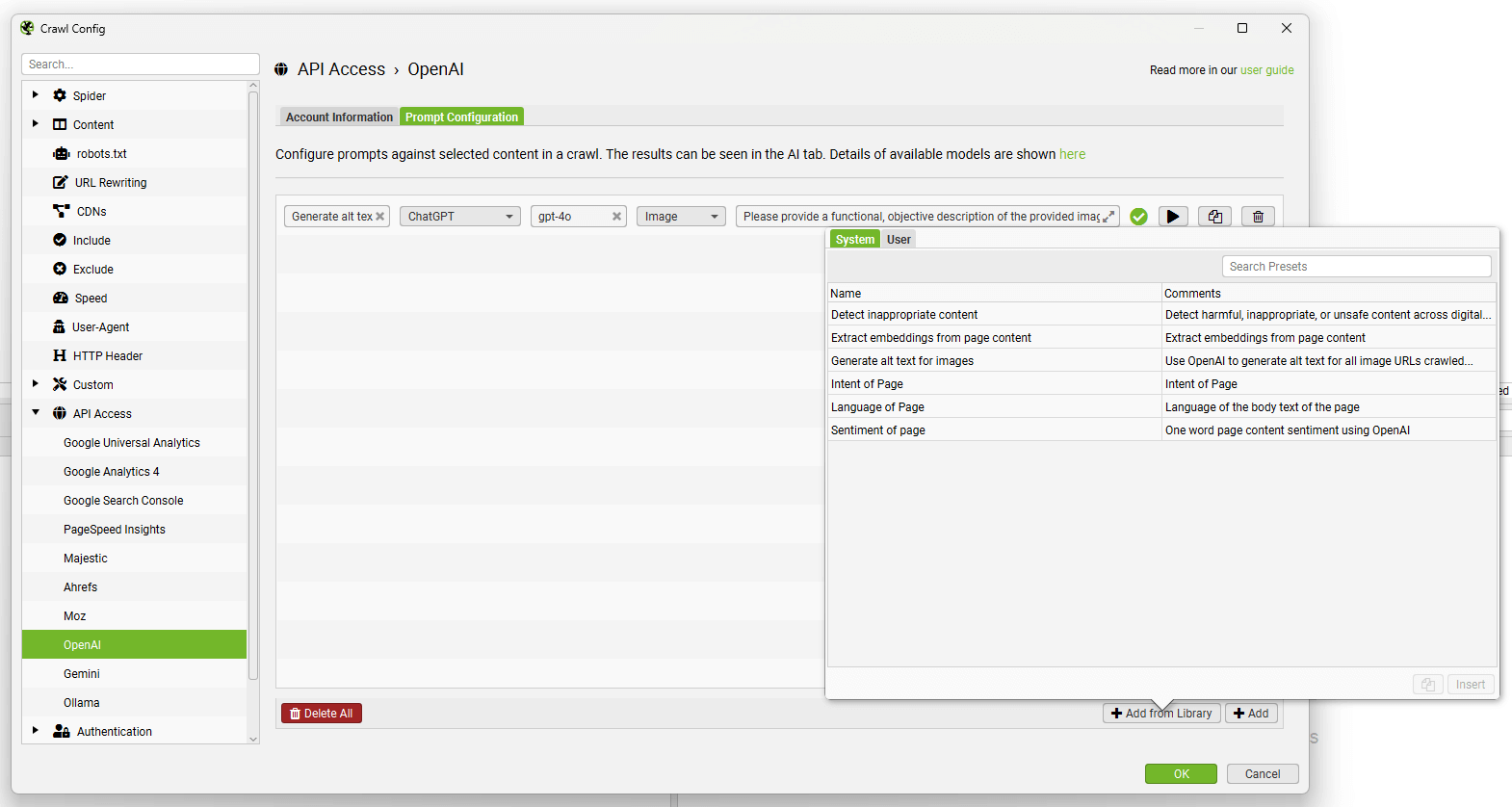
The benefits of using the direct integration over custom JS snippets are –
- You can input your API key once for each AI platform, which will be used for all prompts.
- You don’t need to edit any JavaScript code! You can just select requirements from dropdowns and enter your prompt into the relevant field.
- JavaScript rendering mode isn’t required, data can be returned through any crawl mode.
- The APIs are automatically throttled as per their requirements.
This new AI integration should make it even more efficient to create custom prompts when crawling. We hope users will utilise these new AI capabilities responsibly for genuine ‘value-add’ use cases.
2) Accessibility
You can now perform an accessibility audit in the SEO Spider using the open-source AXE accessibility rule set for automated accessibility validation from Deque.
This is what powers the accessibility best practices seen in Lighthouse and PageSpeed Insights. It should allow users to improve their websites to make them more inclusive, user friendly and accessible for people with disabilities.
Accessibility can be enabled via ‘Config > Spider > Extraction’ (under ‘Page Details’) and requires JavaScript rendering to be enabled to populate the new Accessibility tab.

The Accessibility tab details the number of accessibility violations at different levels of compliance based on the Web Content Accessibility Guidelines (WCAG) set by the W3C.

An accessibility score for each page can also be collected by connecting to Lighthouse via PageSpeed Insights (‘Config > API Access > PSI’).
WCAG compliance levels build upon each other and start from WCAG 2.0 A to 2.0 AA, then 2.0 AAA before moving onto 2.1 AA and 2.2 AA. To reach the highest level of compliance (2.2 AA), all violations in previous versions must also be achieved.
The Accessibility tab includes filters by WCAG with over 90 rules within them to meet that level of compliance at a minimum.

The right-hand Issues tab groups them by accessibility violation and priority, which is based upon the WCAG ‘impact’ level from Deque’s AXE rules and includes an issue description and further reading link.

The lower Accessibility Details tab includes granular information on each violation, the guidelines, impact and location on each page.

You can right-click on any of the violations on the right-hand side, to ‘Show Issue in Browser’ or ‘Show Issue In Rendered HTML’.
All the data including the location on the page can be exported via ‘Bulk Export > Accessibility > All Violations’, or the various WCAG levels.

There’s also an aggregated report under the ‘Reports’ menu.
3) Email Notifications
You can now connect to your email account and send an email on crawl completion to colleagues, clients or yourself to pretend you have lots of friends.
This can be set up via ‘File > Settings > Notifications’ and adding a supported email account.

You can select to ‘Email on Crawl Complete’ for every crawl to specific email address(es).

So many friends.
Alternatively, you can send emails for specific scheduled crawls upon completion via the new ‘Notifications’ tab in the scheduled crawl task as well.

The email sent confirms crawl completion and provides some top-level data from the crawl.

We may expand this functionality in the future to include additional data points and data exports.
Please read about notifications in our user guide.
4) Custom Search Bulk Upload
There’s a new ‘Bulk Add’ option in custom search, which allows you to quickly upload lots of custom search filters, instead of inputting them individually.

If you’re using this feature to find unlinked keywords for internal linking, for example, you can quickly add up to 100 keywords to find on pages using ‘Page Text No Anchors’.

Please see our ‘How to Use Custom Search‘ tutorial for more.
Other Updates
Version 21.0 also includes a number of smaller updates and bug fixes.
- Additional crawl statistics are now available via the arrows in the bottom right-hand corner of the app. Alongside URLs completed and remaining, you can view elapsed and estimated time remaining, as well as crawl start time date and time. This data is available via ‘Reports > Crawl Overview’ as well.
- Custom Extraction has been updated to support not just XPath 1.0, but 2.0, 3.0 and 3.1.
- Scheduling now has ‘Export’ and ‘Import’ options to help make moving scheduled crawl tasks less painful.
- The Canonicals tab has two new issues for ‘Contains Fragment URL’ and ‘Invalid Attribute In Annotation’.
- The Archive Website functionality now supports WARC format for web archiving. The WAR file can be exported and viewed in popular viewers.
- You can now open database crawls directly via the CLI using the –load-crawl argument with the database ID for the crawl. The database ID can be collected in the UI by right-clicking in the ‘File > Crawls’ table and pasting it out, or viewed in the CLI using the cli –list-crawls argument.
- There’s a new right click ‘Show Link In Browser’ and ‘Show Link in HTML’ option in Inlinks and Outlinks tab to make it more efficient to find specific links.
That’s everything for version 21.0!
Thanks to everyone for their continued support, feature requests and feedback. Please let us know if you experience any issues with this latest update via our support.

Leave a Reply