We’re delighted to announce Screaming Frog SEO Spider version 19.0, codenamed internally as ‘Peel’.
This update contains a number of significant updates, new features and enhancements based upon user feedback and a little internal steer.
Let’s take a look at what’s new.
1) Updated Design
While subtle, the GUI appearance has been refreshed in look and feel, with crawl behaviour functions (crawl a subdomain, subfolder, all subdomains etc) moved to the main nav for ease.
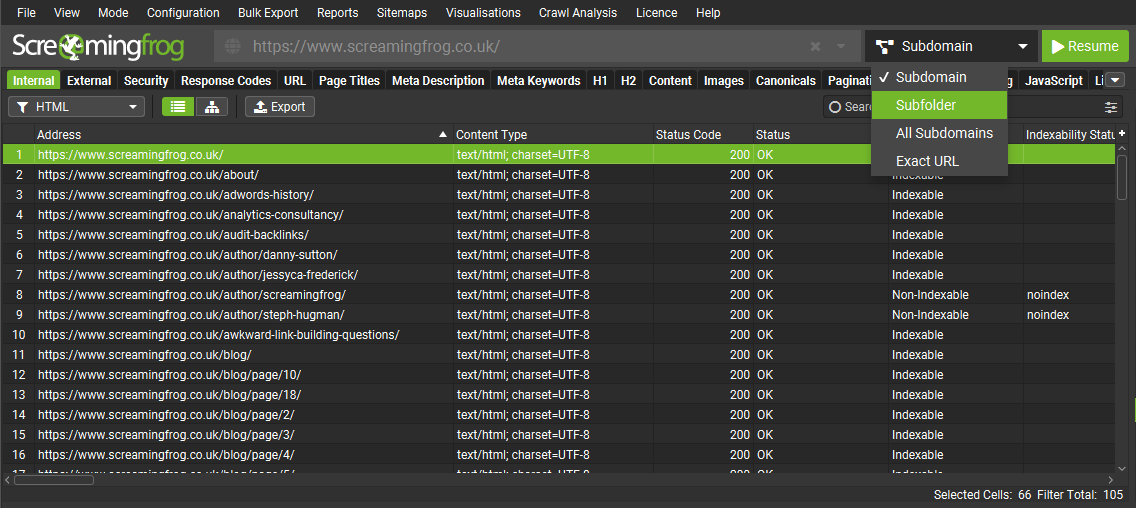
These options had previously been within the configuration, so this makes them accessible to free users as well.
There’s now alternate row colours in the main tables, updated icons and even the Twitter icon and link have been removed (!). While the UX, tabs and filters are much the same, the configuration has received an overhaul.
2) Unified Config
The configuration has been unified into a single dialog, with links to each section. This makes adjusting the config more efficient than opening and closing each separately. The naming and location of config items should be familiar to existing users, while being easier to navigate for new users.
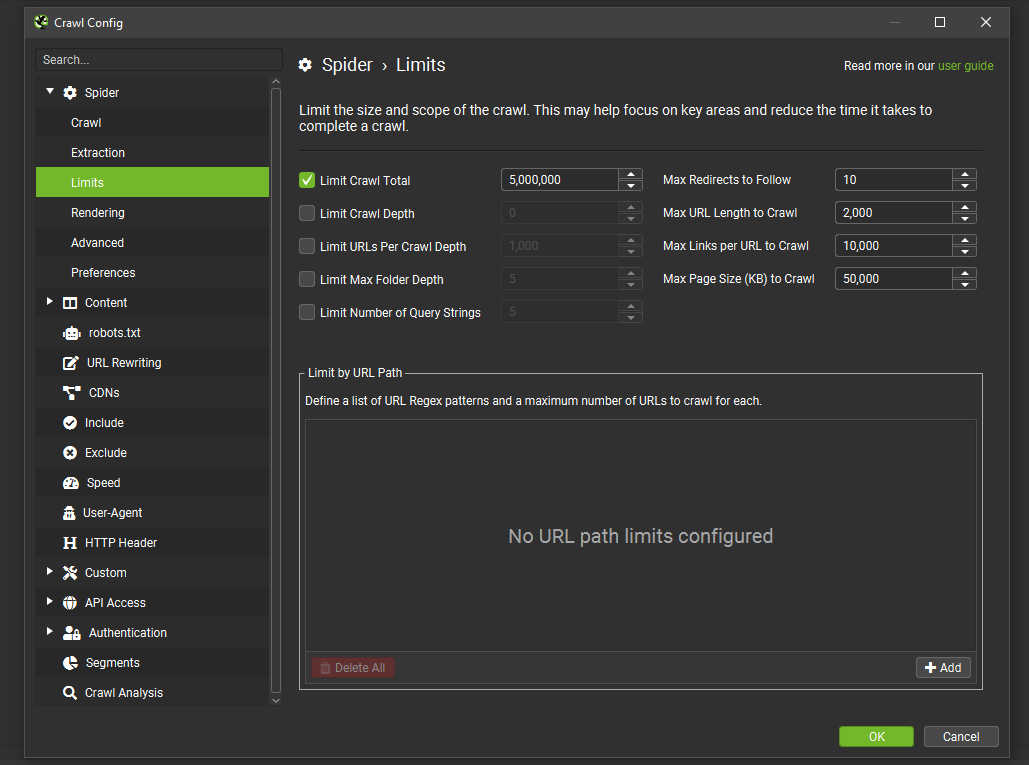
There’s been a few small adjustments, such as saving and loading configuration profiles now appearing under ‘Configuration’, rather than the ‘File’ menu.
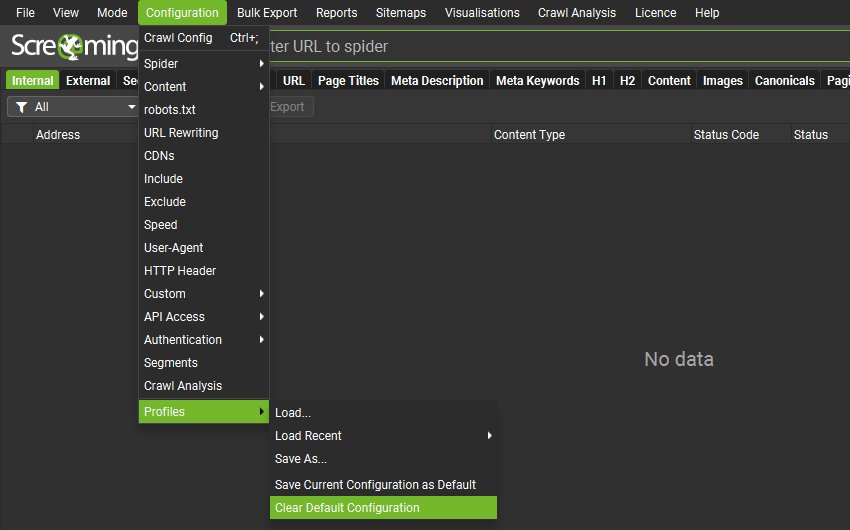
System settings such as user interface, language, storage mode and more are available under ‘File > Settings’, in their own unified configuration.
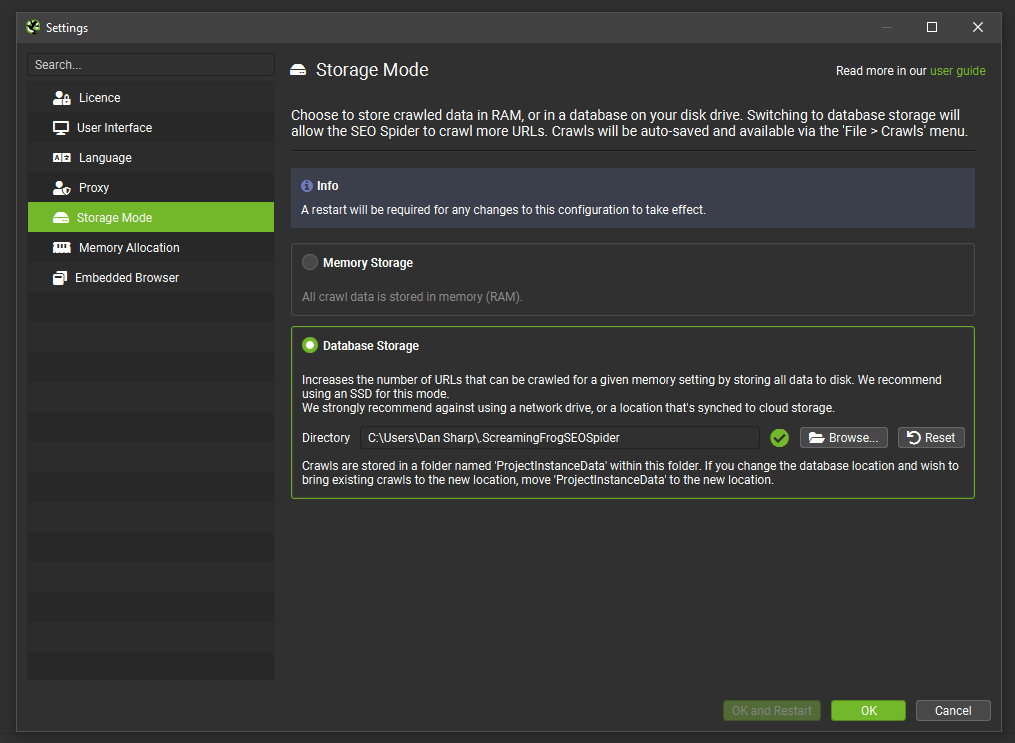
You can also ‘Cancel’ any changes made by using the cancel button on the configuration dialog.
3) Segments
You can now segment a crawl to better identify and monitor issues and opportunities from different templates, page types, or areas of priority.
The segmentation config can be accessed via the config menu or right-hand ‘Segments’ tab, and it allows you to segment based upon any data found in the crawl, including data from APIs such as GA or GSC, or post-crawl analysis.
You can set up a segment at the start, during, or at the end of a crawl. There’s a ‘segments’ column with coloured labels in each tab.
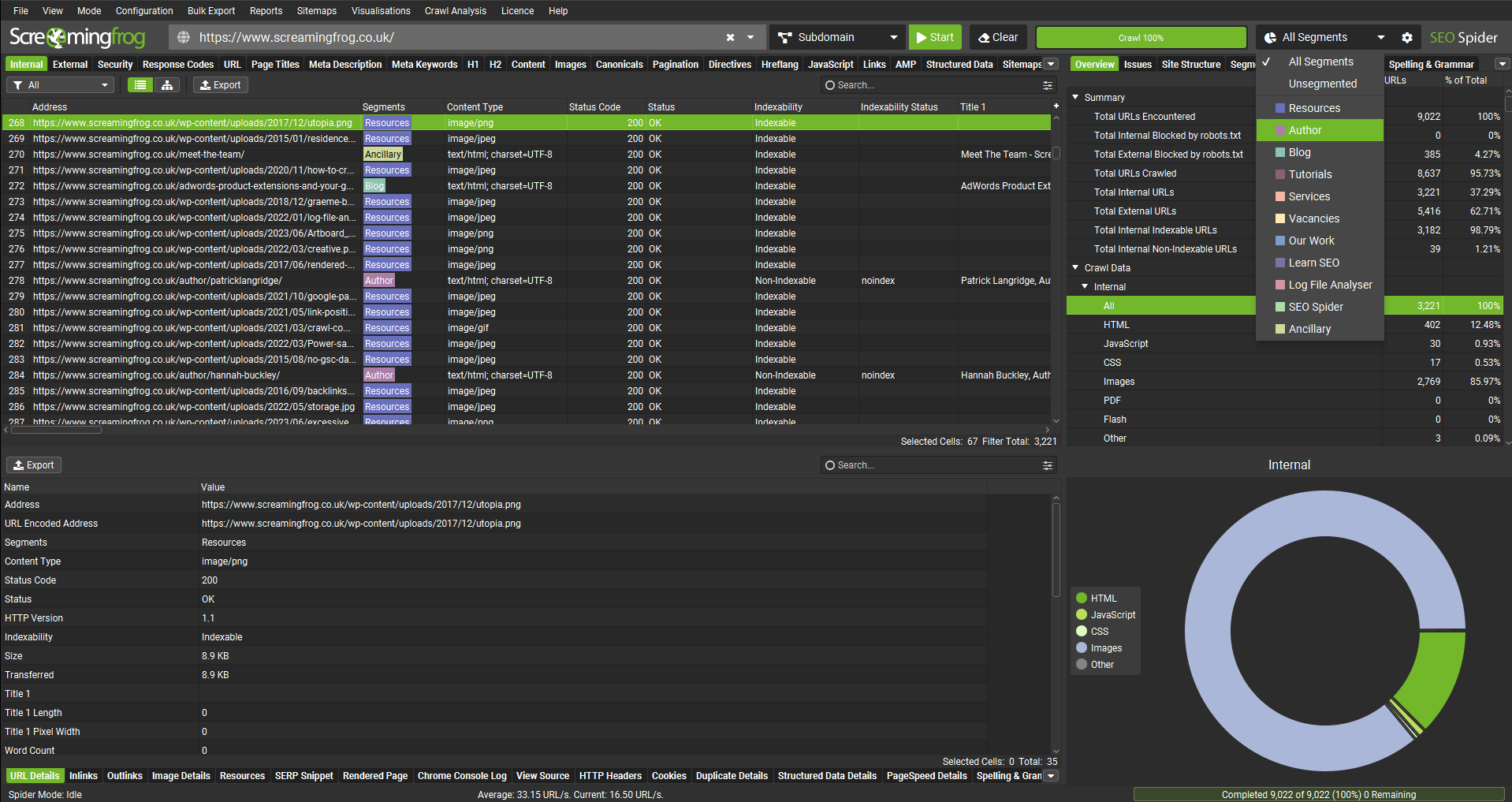
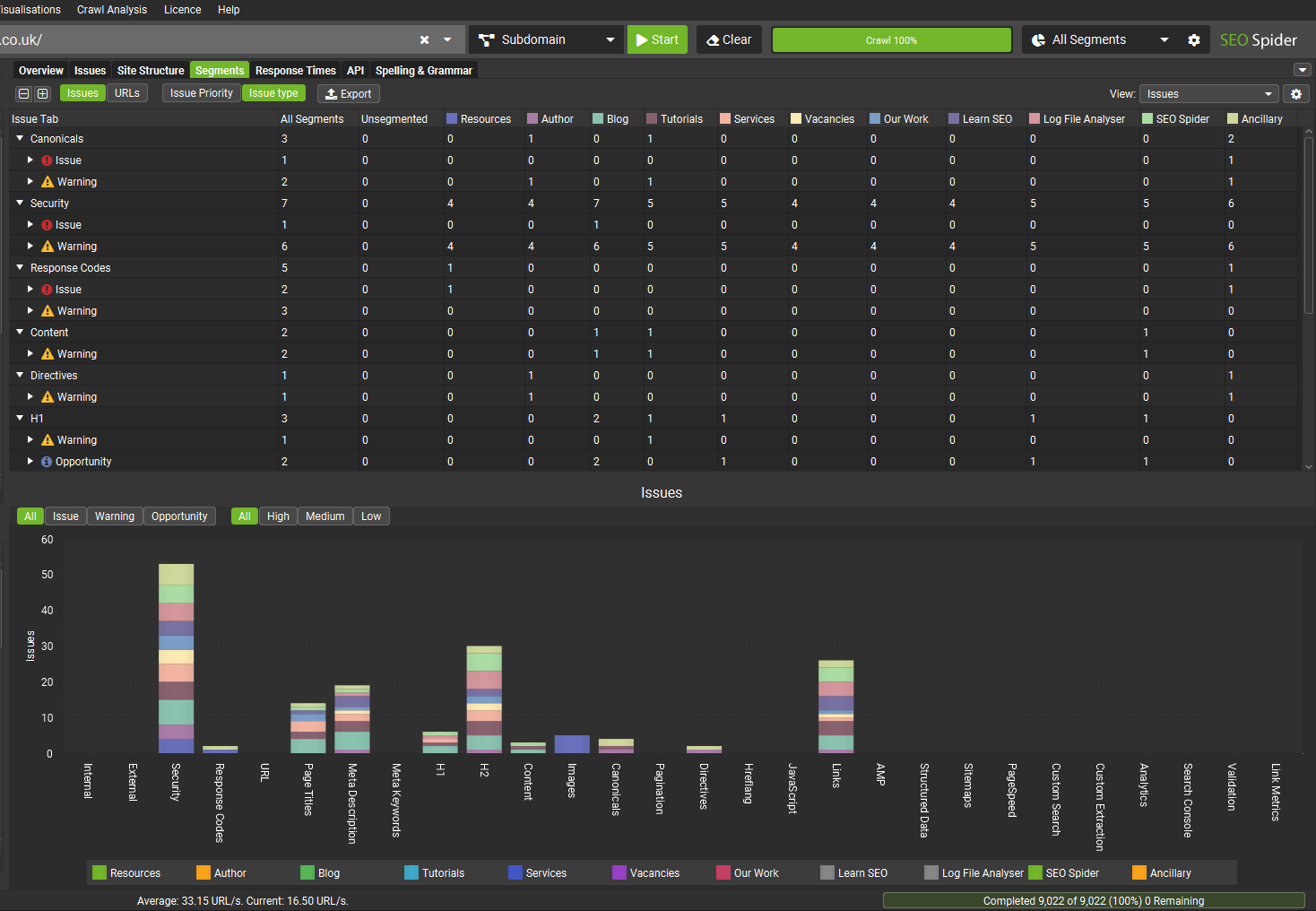
When segments are set up, the right hand ‘Issues’ tab includes a segments bar, so you can quickly see where on the site the issues are at a glance.
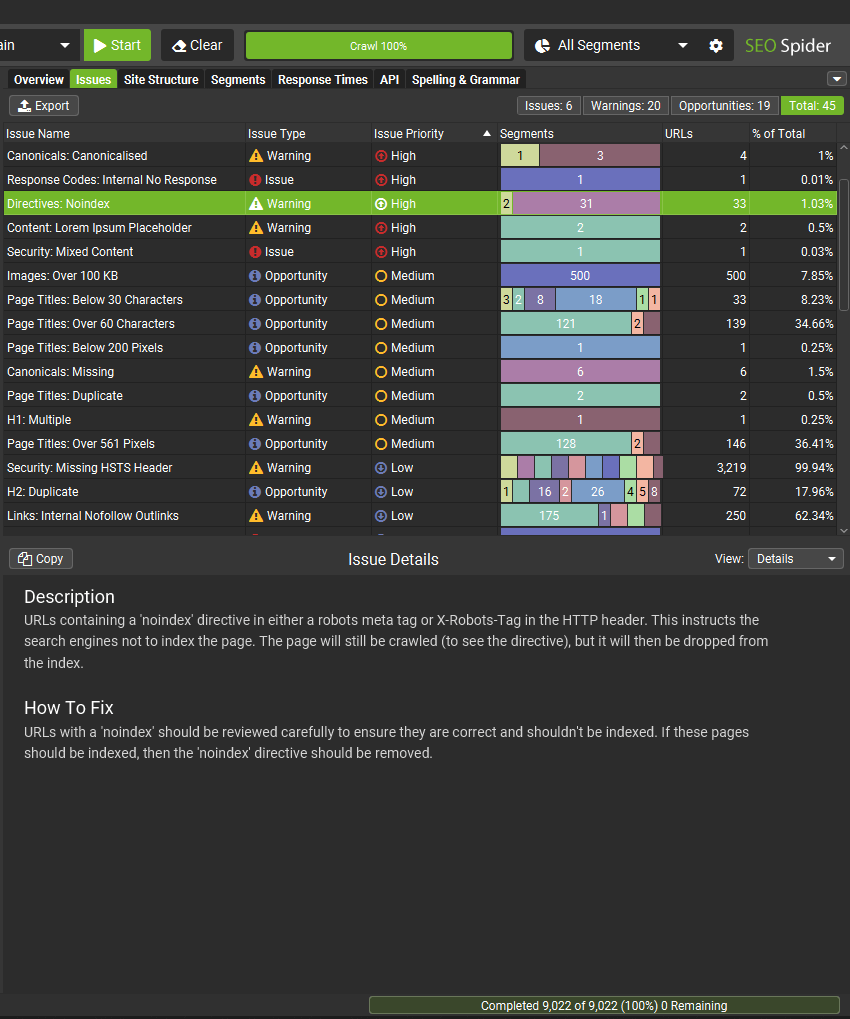
You can then use the right-hand segments filter, to drill down to individual segments.
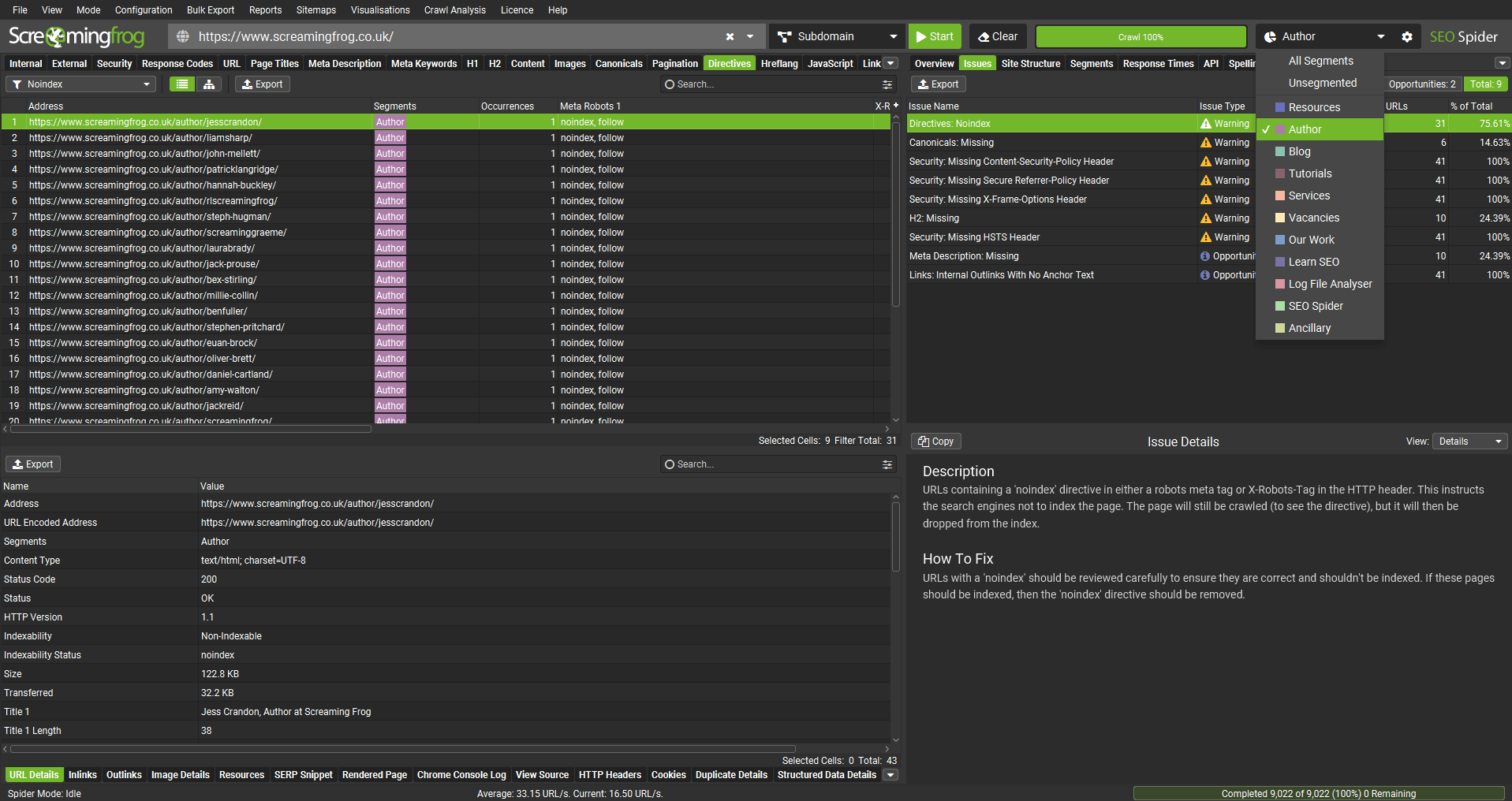
There’s a new right-hand ‘Segments’ tab with an aggregated view, to quickly see where issues are by segment.
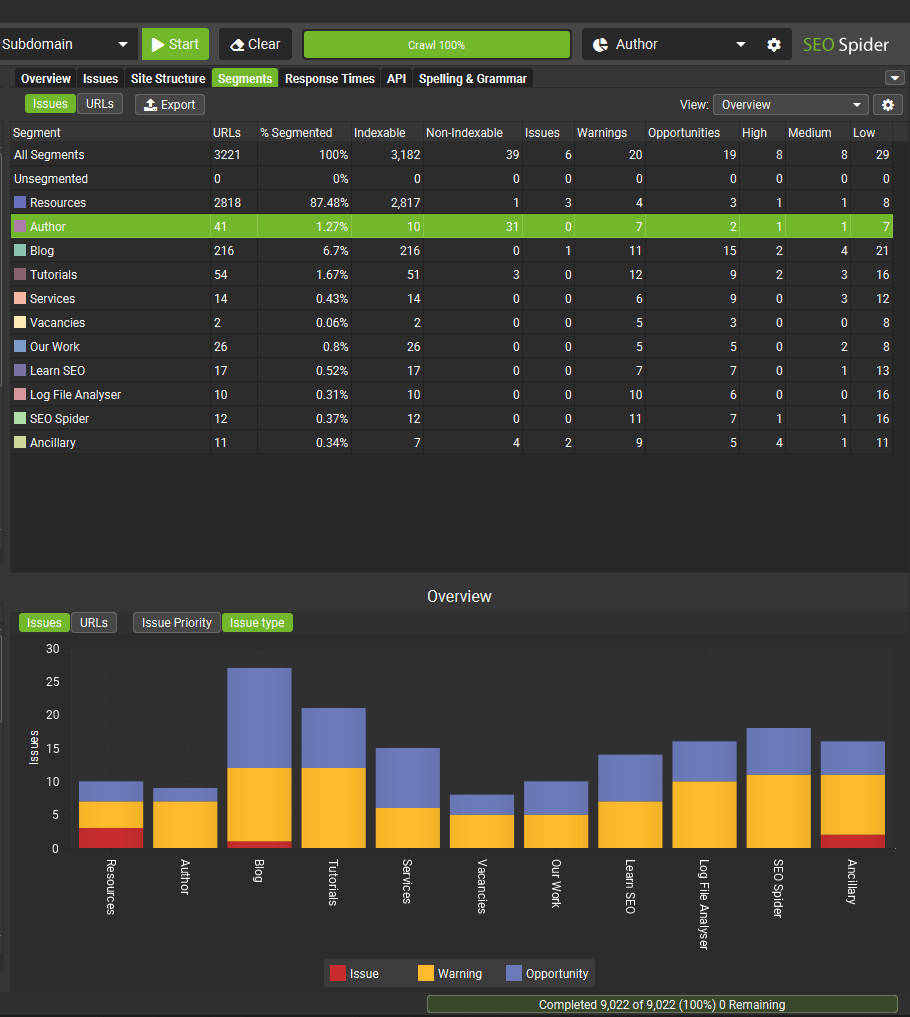
You can use the Segments tab ‘view’ filter to better analyse items like crawl depth by segment.
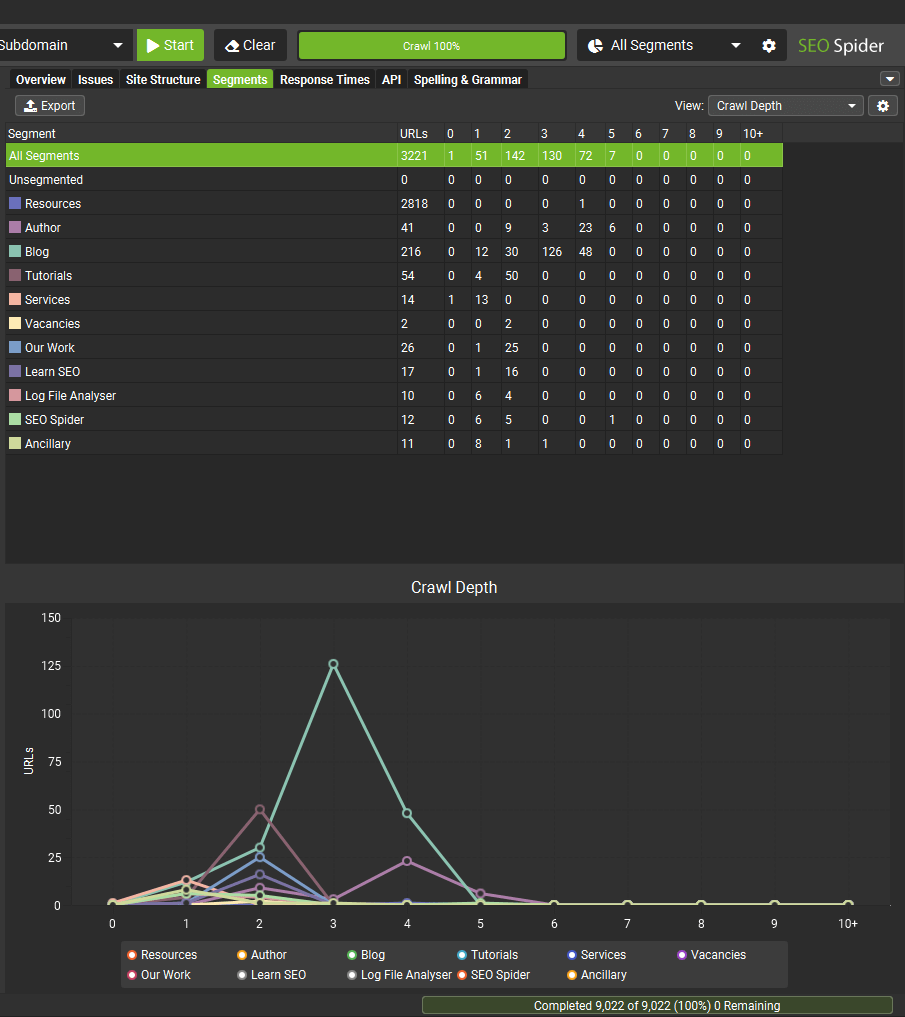
Or which segments have different types of issues.
Once set-up, segments can be saved with the configuration. Segments are fully integrated into various other features in the SEO Spider as well.
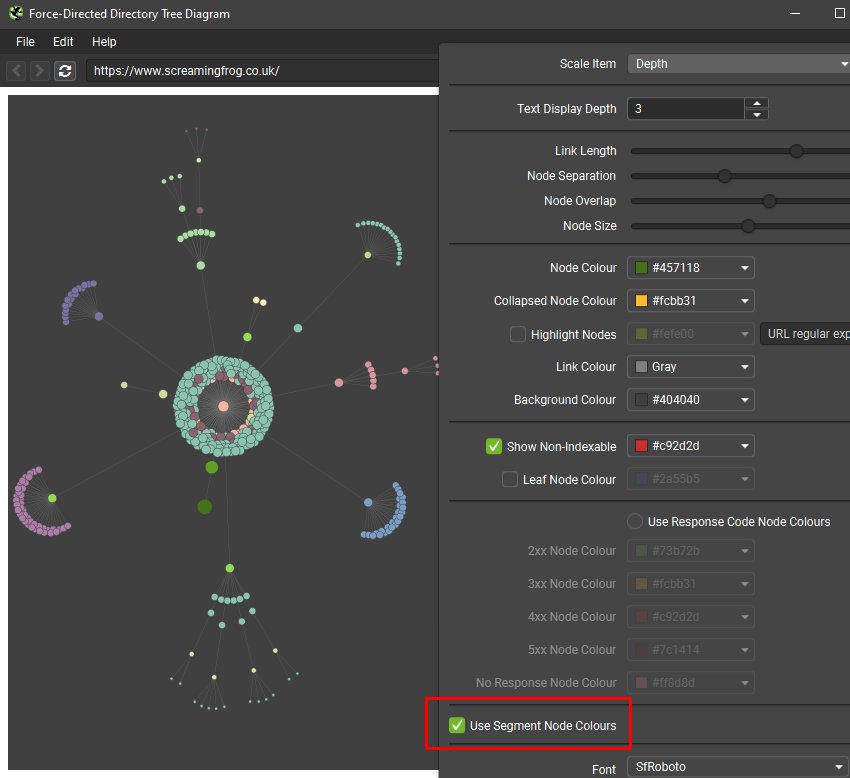
In crawl visualisations, you can now choose to colour by segment.
You can also choose to create XML Sitemaps by segment, and the SEO Spider will automatically create a Sitemap Index file referencing each segmented sitemap.
Within the Export for Looker Studio for automated crawl reports, a separate sheet will also be automatically created for each segment created. This means you can monitor issues by segment in a Looker Studio Crawl Report as well.
4) Visual Custom Extraction
Custom Extraction is a super powerful feature in the SEO Spider, but it’s also quite an advanced feature and many users couldn’t care less about learning XPath or CSSPath (understandably, so).
To help with this, you’re now able to open a web page in our inbuilt browser and select the elements you wish to extract from either the web page, raw HTML or rendered HTML. We’ll then formulate the correct XPath/CSSPath for you, and provide a range of other options as well.
Just click the web page icon to the side of an extractor to bring up the browser –
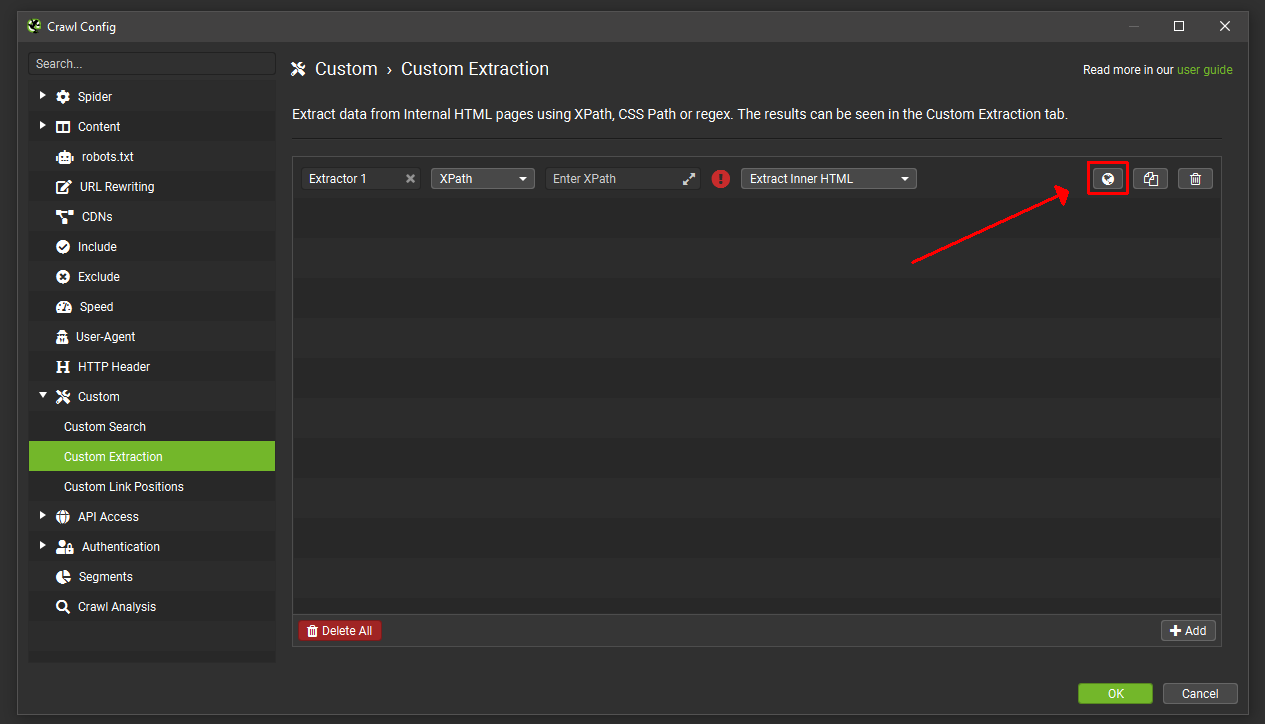
Input the URL you wish to scrape, and then select the element on the page. The SEO Spider will then highlight the area you wish to extract, and create an expression for you, with a preview of what will be extracted based upon the raw or rendered HTML.
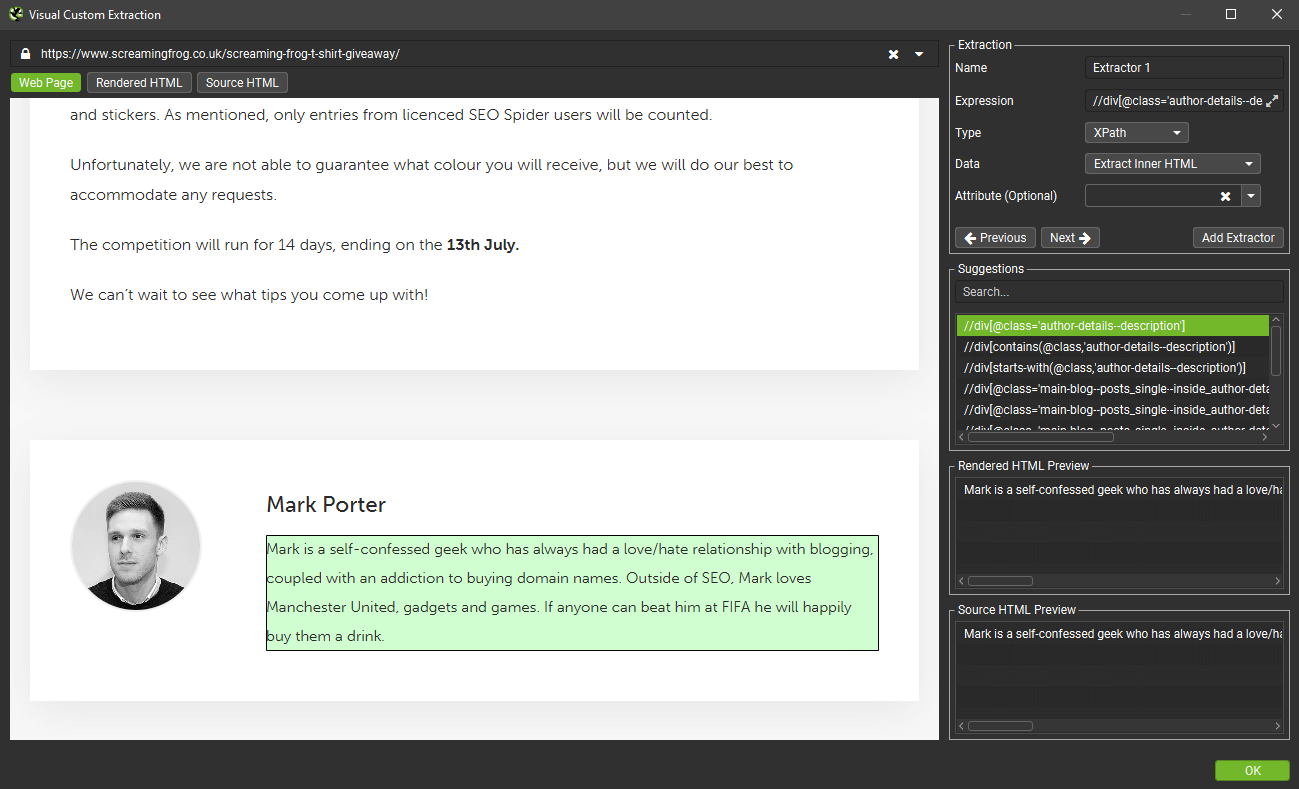
You can switch to Rendered or Source HTML view and pick a line of HTML as well. For example, if you wish to extract the ‘content’ of an OG tag –
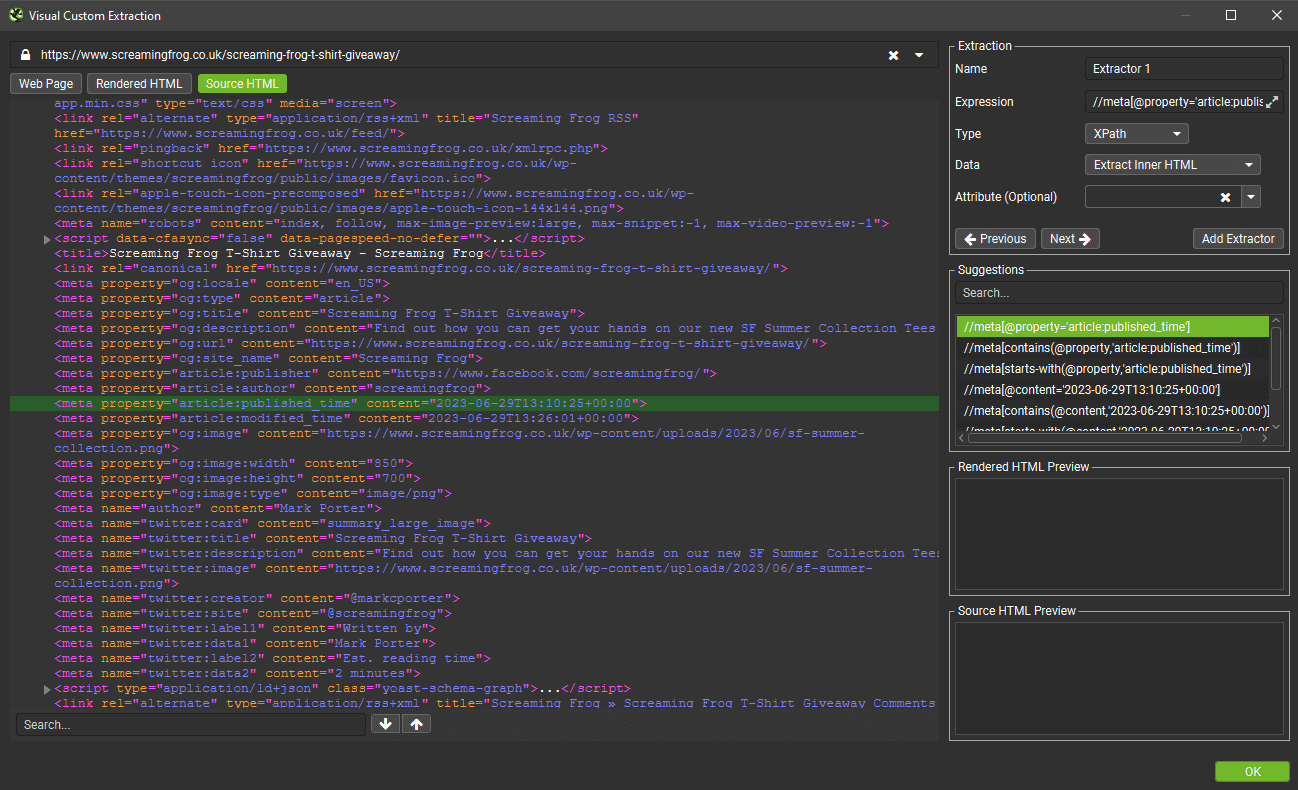
You can then select the attribute you wish to extract from the dropdown, and it will formulate the expression for you.
In this case below, it will scrape the published time, which is shown in the source and rendered HTML previews after selecting the ‘content’ attribute.
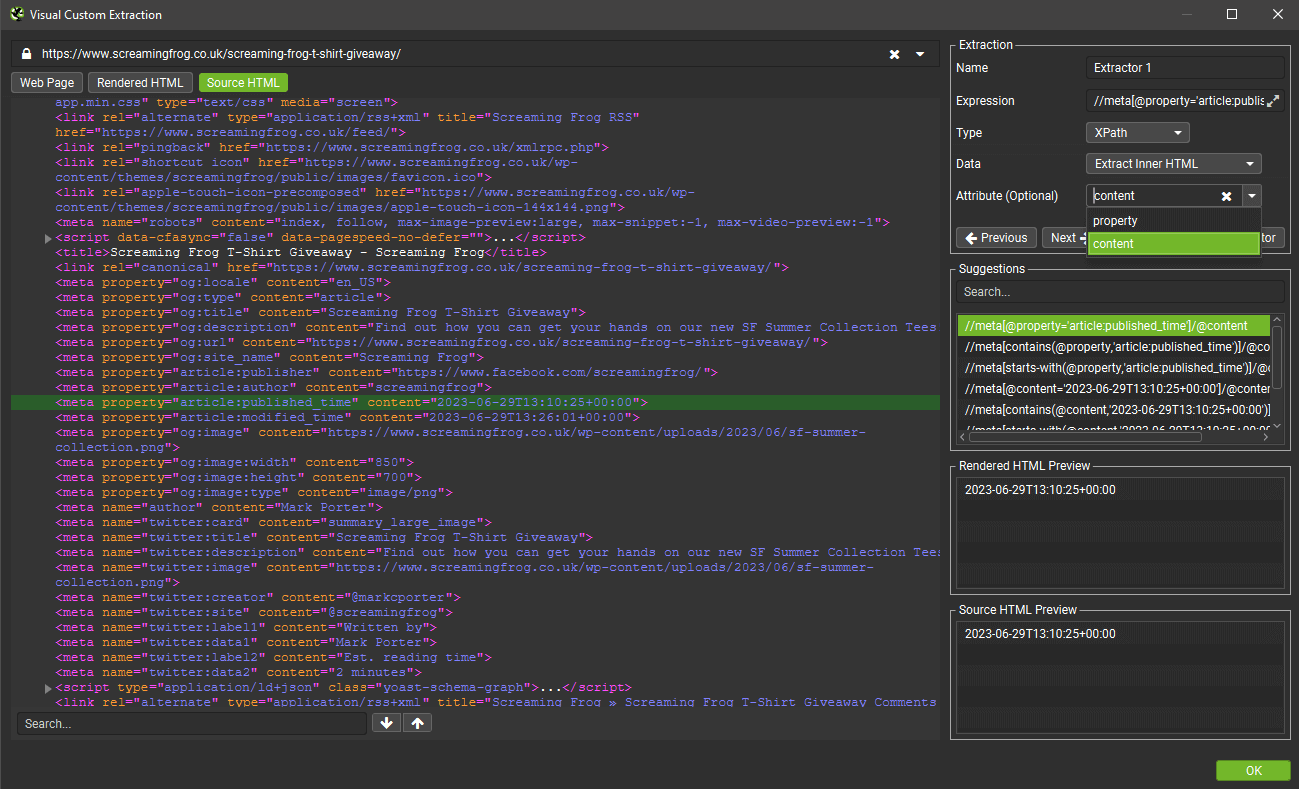
For those of you that have mastered XPath, CSSPath and regex, you can continue to input your expressions in the same way as before.
At the moment this new feature doesn’t help with extracting JS, but we plan on extending this functionality to help scrape conceivably anything from the HTML.
5) 3D Visualisations
If you’re a fan of our crawl visualisations, then you’ll dig the introduction of a 3D Force-Directed Crawl Diagram, and 3D Force-Directed Directory-Tree Diagram.
They work in the same way as existing crawl and directory-tree visualisations, except (yes, you guessed it) they are 3D and allow you to move around nodes like you’re in space, and ‘within’ the visualisation itself.
These visualisations are restricted to 100k URLs currently, otherwise your machine may explode. At 100k URLs, the visualisation is also slightly bonkers.

Do they help you identify more issues, more effectively? Not really.
But they are fun, and sometimes that’s enough.
6) New Filters & Issues
There’s a variety of new filters and issues available across existing tabs that help better filter data, or communicate issues discovered.
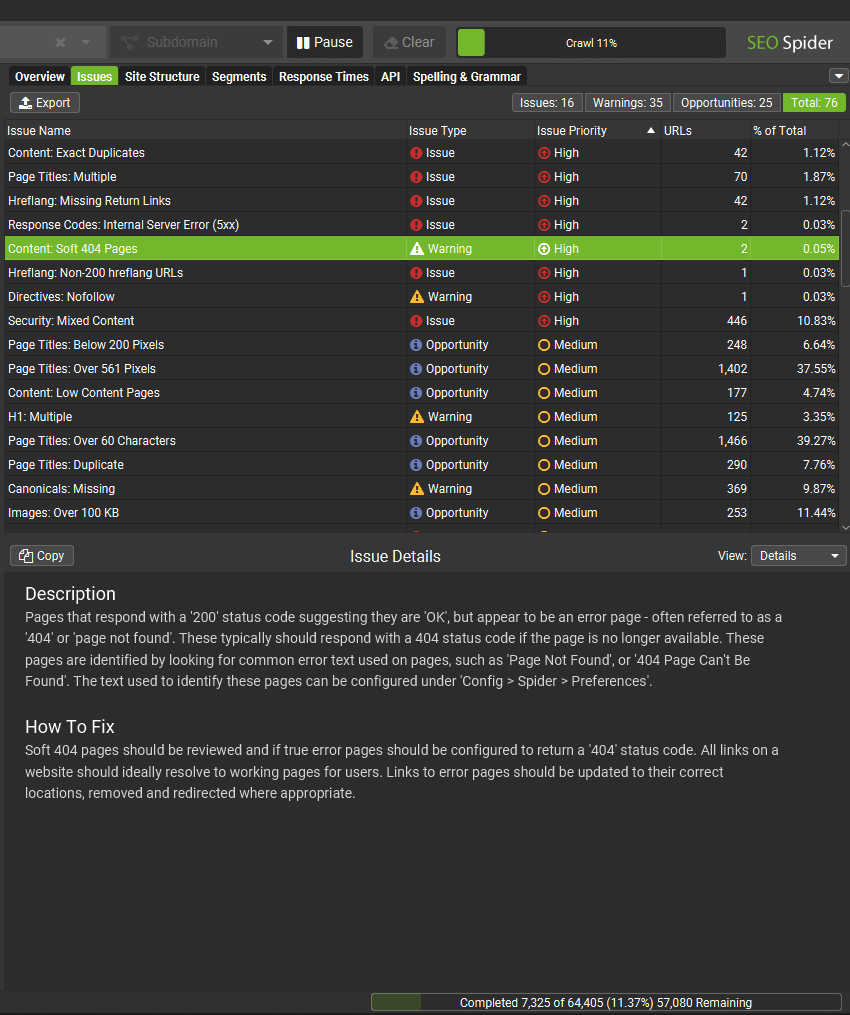
The new filters available include the following –
- ‘URL > GA Tracking Parameters’ – URLs that contain Google Analytics tracking parameters. In addition to creating duplicate pages that must be crawled, using tracking parameters on links internally can overwrite the original session data. utm= parameters strip the original source of traffic and starts a new session with the specified attributes. _ga= and _gl= parameters are used for cross-domain linking and identify a specific user, including this on links prevents a unique user ID from being assigned.
- ‘Page Titles > Outside <head>’ – Pages with a title element that is outside of the head element in the HTML. The page title should be within the head element, or search engines may ignore it. Google will often still recognise the page title even outside of the head element, however this should not be relied upon.
- ‘Meta Description > Outside <head>’ – Pages with a meta description that is outside of the head element in the HTML. The meta description should be within the head element, or search engines may ignore it.
- ‘H1 > Alt Text in h1’ – Pages which have image alt text within an h1. This can be because text within the image is considered as the main heading on the page, or due to inappropriate mark-up. Some CMS templates will automatically include an h1 around a logo across a website. While there are strong arguments that text rather than alt text should be used for headings, search engines may understand alt text within an h1 as part of the h1 and score accordingly.
- ‘H1 > Non-sequential’ – Pages with an h1 that is not the first heading on the page. Heading elements should be in a logical sequentially-descending order. The purpose of heading elements is to convey the structure of the page and they should be in logical order from h1 to h6, which helps navigating the page and users that rely on assistive technologies.
- ‘H2 > Non-sequential’ – Pages with an h2 that is not the second heading level after the h1 on the page. Heading elements should be in a logical sequentially-descending order. The purpose of heading elements is to convey the structure of the page and they should be in logical order from h1 to h6, which helps navigating the page and users that rely on assistive technologies.
- ‘Content > Soft 404 Pages’ – Pages that respond with a ‘200’ status code suggesting they are ‘OK’, but appear to be an error page – often referred to as a ‘404’ or ‘page not found’. These typically should respond with a 404 status code if the page is no longer available. These pages are identified by looking for common error text used on pages, such as ‘Page Not Found’, or ‘404 Page Can’t Be Found’. The text used to identify these pages can be configured under ‘Config > Spider > Preferences’.
- ‘Content > Lorem Ipsum Placeholder’ – Pages that contain ‘Lorem ipsum’ text that is commonly used as a placeholder to demonstrate the visual form of a webpage. This can be left on web pages by mistake, particularly during new website builds.
- ‘Images > Missing Size Attributes’ – Image elements without dimensions (width and height size attributes) specified in the HTML. This can cause large layout shifts as the page loads and be frustrating experience for users. It is one of the major reasons that contributes to a high Cumulative Layout Shift (CLS).
- ‘Images > Incorrectly Sized Images’ – Images identified where their real dimensions (WxH) do not match the display dimensions when rendered. If there is an estimated 4kb file size difference or more, the image is flagged for potential optimisation. In particular, this can help identify oversized images, which can contribute to poor page load speed. It can also help identify smaller sized images, that are being stretched when rendered.
- ‘Canonicals > Outside <head>’ – Pages with a canonical link element that is outside of the head element in the HTML. The canonical link element should be within the head element, or search engines will ignore it.
- ‘Directives > Outside <head>’ – Pages with a meta robots that is outside of the head element in the HTML. The meta robots should be within the head element, or search engines may ignore it. Google will typically still recognise meta robots such as a ‘noindex’ directive, even outside of the head element, however this should not be relied upon.
- ‘Hreflang > Outside <head>’ – Pages with an hreflang link element that is outside of the head element in the HTML. The hreflang link element should be within the head element, or search engines will ignore it.
- ‘JavaScript > Pages with JavaScript Errors’ – Pages with JavaScript errors captured in the Chrome DevTools console log during page rendering. While JavaScript errors are common and often have little effect on page rendering, they can be problematic – both in search engine rendering, which can hinder indexing, and for the user when interacting with the page. View console error messages in the lower ‘Chrome Console Log’ tab, view how the page is rendered in the ‘Rendered Page’ tab, and export in bulk via ‘Bulk Export > JavaScript > Pages With JavaScript Issues’.
- ‘Validation > <body> Element Preceding <html>’ – Pages that have a body element preceding the opening html element. Browsers and Googlebot will automatically assume the start of the body and generate an empty head element before it. This means the intended head element below and its metadata will be seen in the body and ignored.
In some cases new data is collected and reported alongside the new filter. For example, we now collect image element dimension attributes, display dimensions and their real dimensions to better identify oversized images, which can be seen in the image details tab and various bulk exports.
Other Updates
Version 19.0 also includes a number of smaller updates and bug fixes.
- There’s a new ‘focus’ mode under ‘View’ in the top-level menu, that auto hides tabs that are not in use to reduce clutter.
- You can enable JavaScript error reporting (‘Config > Spider > Rendering’) and view JS errors, warnings and issues using the lower ‘Chrome Console Log’ tab.
- Pre-set user-agents have been updated to include more Google crawler variants, such as Googlebot Image, News, Google-Inspection Tool etc. Thanks to Jaroslav for the suggestion.
- The SERP snippet tab has been updated to match Google’s latest SERP design, including favicon.
- The Windows installer has been updated with more options around saving a shortcut etc.
- Updated Forms Based Authentication to support Local Storage.
- Introduced a configurable trust store to allow users to connect to GA/GSC via outbound proxies.
- Java has been updated to 17.0.7 and all dependencies have been updated to latest versions.
- Updated another million Google rich result features due to changes for structured data validation.
That’s everything for this release!
Thanks to everyone for their continued support, feature requests and feedback. Please let us know if you expericence any issues with version 19.0 of the SEO Spider via our support.
Leave a Reply