We’re pleased to announce Screaming Frog SEO Spider version 17.0, codenamed internally as ‘Lionesses’.
Since releasing the URL Inspection API integration in the SEO Spider and the launch of version 5 of the Log File Analyser, we’ve been busy working on the next round of prioritised features and enhancements.
Here’s what’s new in our latest update.
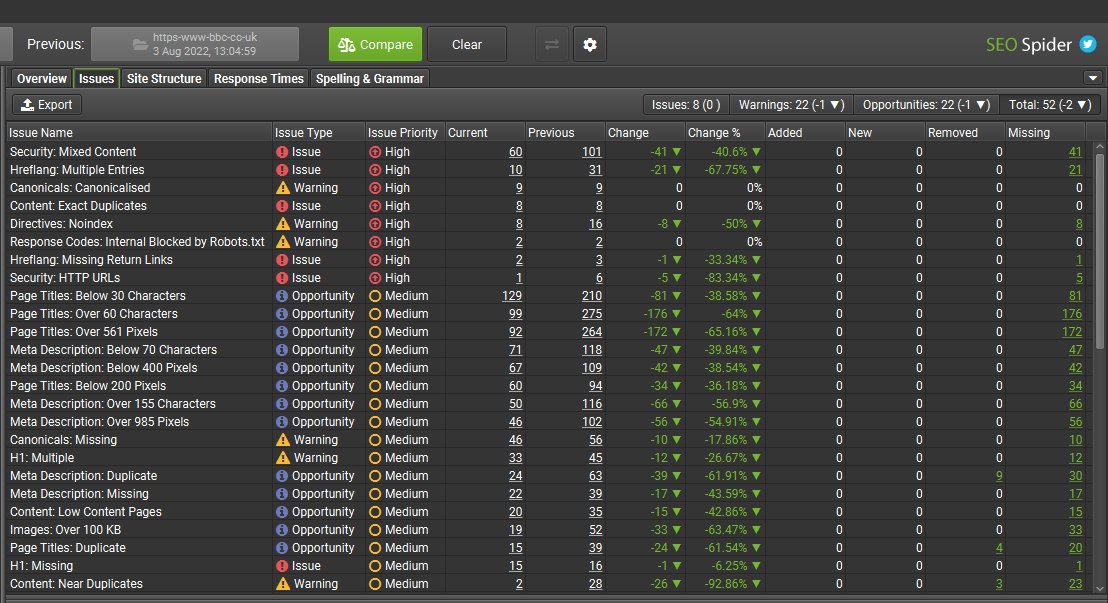
1) Issues Tab
There’s a new ‘Issues’ right-hand tab, which details issues, warnings and opportunities discovered.
This tab has been introduced to help better direct users to potential problems and areas for improvement, based upon existing filters from the ‘Overview’ tab.
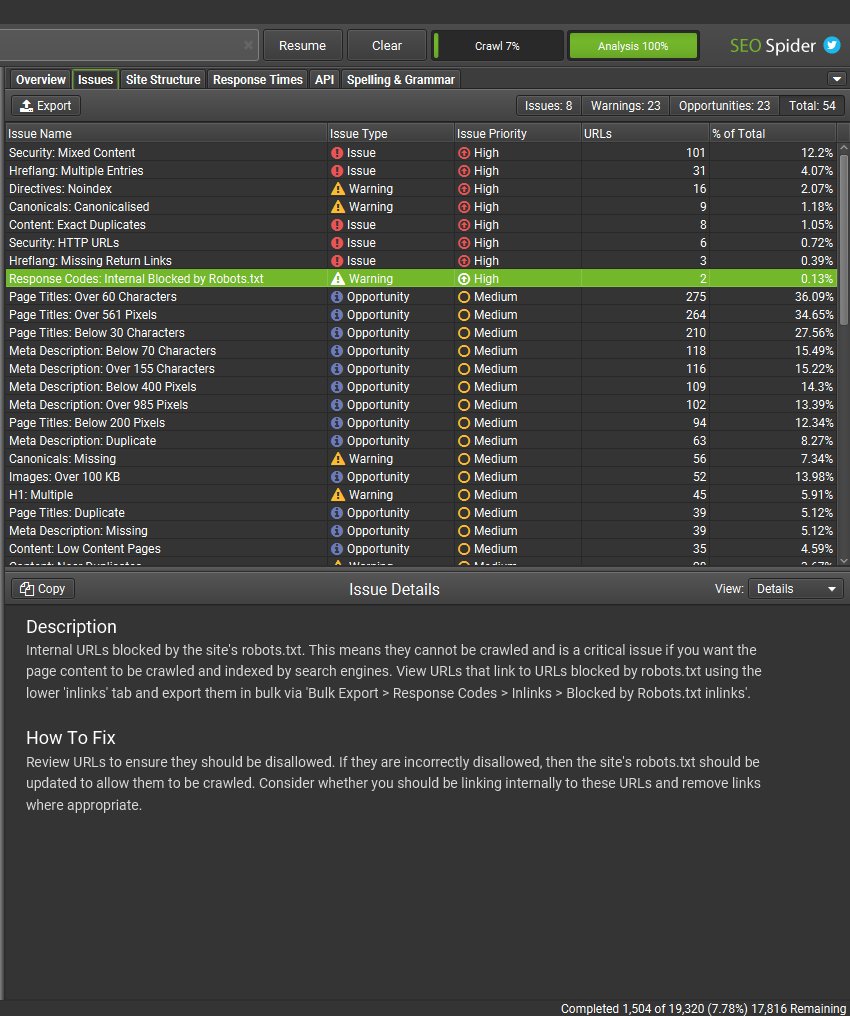
An in-app explanation of each issue and potential actions is provided in English, German, Spanish, French and Italian.
Each issue has a ‘type’ and an estimated ‘priority’ based upon the potential impact.
- Issues are an error or issue that should ideally be fixed.
- Opportunities are potential areas for optimisation and improvement.
- Warnings are not necessarily an issue, but should be checked – and potentially fixed.
E.g – An ‘Internal URL Blocked by Robots.txt’ will be classed as a ‘warning’, but with a ‘High’ priority as it could potentially have a big impact if incorrectly disallowed.
For experienced users, the new Issues tab is a useful way to quickly identify top-level problems and dive straight into them as an alternative to the Overview tab. For users with less SEO expertise, it will help provide more direction and guidance on improving their website.
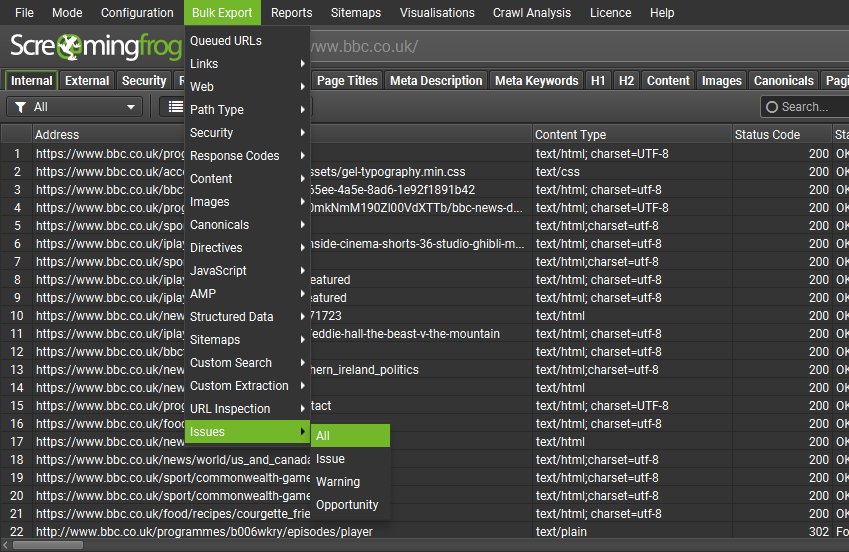
All Issues can be exported in bulk via ‘Bulk Export > Issues > All’. This will export each issue discovered (including their ‘inlinks’ variants for things like broken links) as a separate spreadsheet in a folder (as a CSV, Excel and Sheets).
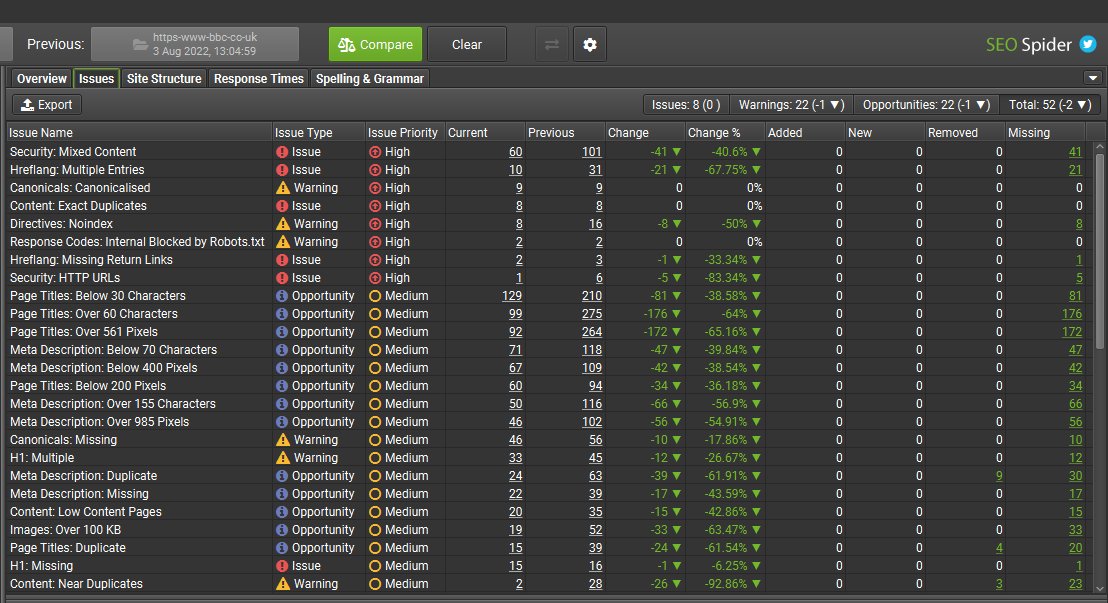
The new Issues tab also works with crawl comparison similar to the Overview tab, to allow users to identify where issues have changed and monitor progress over time.
The SEO Spider has always been built for experts and we have been reticent to ever tell our users how to do SEO, as SEO requires context. The new issues tab does not replace SEO expertise and a professional who has that context of the business, strategy, objectives, resource, website and nuances related to SEO and prioritising what’s important.
The new issues tab should provide helpful hints and support for an SEO who can make sense of the data and interpret it into appropriate prioritised actions.
2) Links Tab
There’s a new ‘Links’ tab which helps better identify link-based issues, such as pages with a high crawl-depth, pages without any internal outlinks, pages using nofollow on internal links, or non-descriptive anchor text.
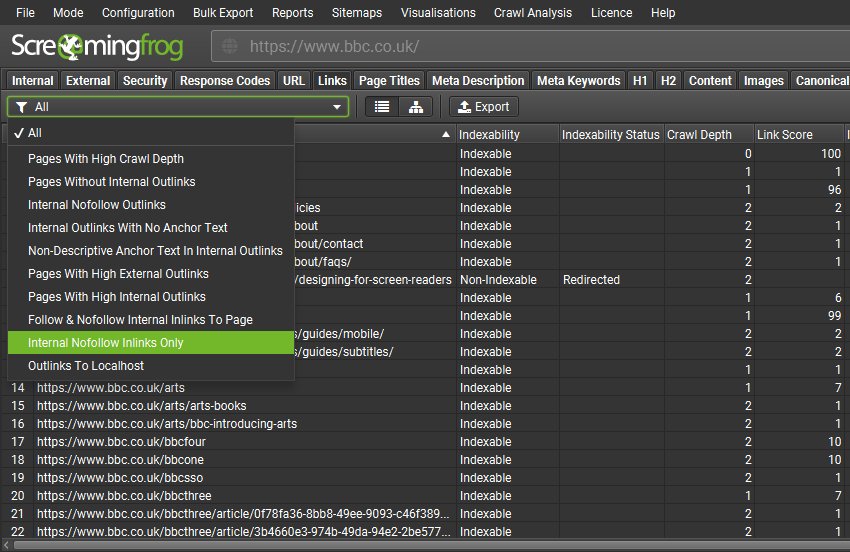
Filters such as ‘high’ internal and external outlinks and non-descriptive anchor text can be customised under ‘Config > Spider > Preferences’ to user-preferred limits.
All data can be exported alongside source pages via the ‘Bulk Export > Links’ menu as well.
3) New Limits
Users are now able to control the number of URLs crawled by URL Path for improved crawl control and sampling of template types.
Under ‘Config > Spider > Limits’ there’s now a ‘Limit by URL Path’ configuration to enter a list of URL patterns and the maximum number of pages to crawl for each.
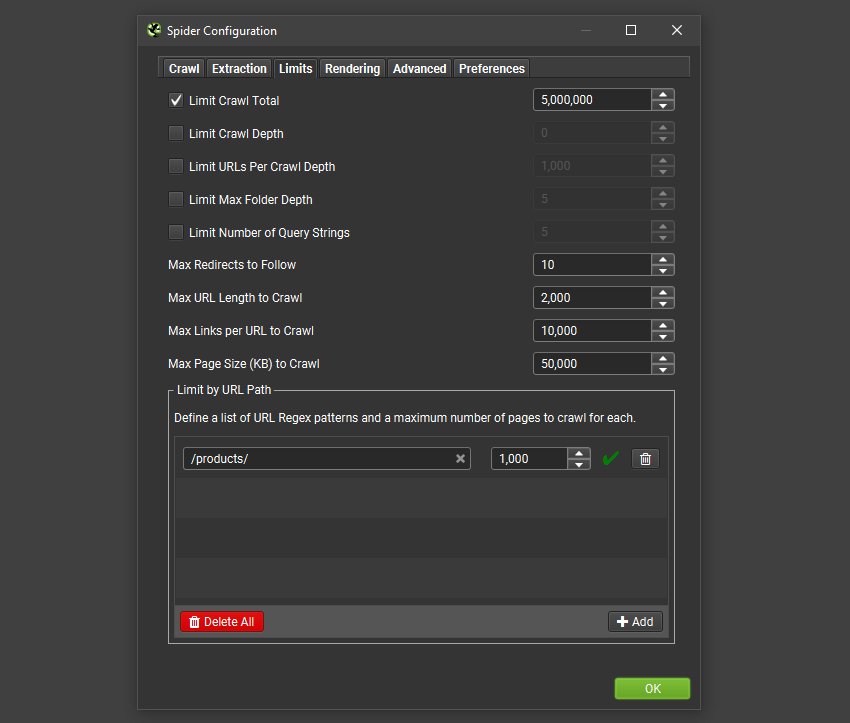
In the example above a maximum of 1,000 product URLs will be crawled, which will be enough of a sample to make smarter decisions.
Users can also now ‘Limit URLs Per Crawl Depth’, which can help with better sampling in some scenarios.
4) ‘Multiple Properties’ Config For URL Inspection API
The URL Inspection API is limited to 2k queries per property a day by Google.
However, it’s possible to have multiple verified properties (subdomains or subfolders) for a website, where each individual property will have a 2k query limit.
Therefore, in the URL Inspection API configuration (‘Config > API Access > GSC > URL Inspection’) users can now select to use ‘multiple properties’ in a single crawl. The SEO Spider will automatically detect all relevant properties in the account, and use the most specific property to request data for the URL.
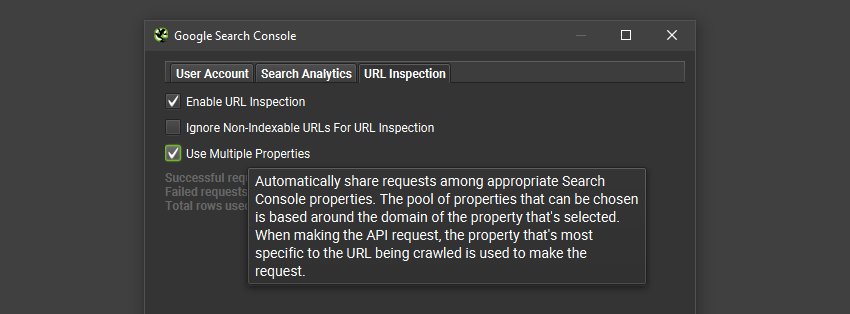
This means it’s now possible to get far more than 2k URLs with URL Inspection API data in a single crawl, if there are multiple properties set up – without having to perform multiple crawls.
Please use responsibly. This feature wasn’t built for the purpose to circumvent Google’s limits and motivate users to create many different properties to get indexing data for every URL on a website. Google may adjust this limit (to domain etc) if it’s abused.
5) Apple Silicon Version & RPM for Fedora
There’s now a native Apple Silicon version available for users on M1/2 macs, and an RPM for Fedora Linux users.
In limited internal testing of the native Silicon version we found that:
- Crawling a locally hosted site with very little latency resulted in the crawl running twice as quickly.
- Loading in a saved crawl was 4 times faster.
The native experience is just so much smoother overall in comparison to using the Rosetta2 emulation layer.
6) Detachable Tabs
All tabs are now detachable. Users can right-click and ‘detach’ any tab from the main UI and move to a preferred position (across multiple screens).
This is pretty cool for users that like to keep one eye on a crawl while doing other things, or analysing all the things at once.
There are options to ‘re-attach’, ‘pin’ – and reset all tabs back to normal when it’s all too much, too.
Other Updates
Version 17.0 also includes a number of smaller updates and bug fixes.
- The ‘Response Codes’ tab now has an additional ‘Internal’ and ‘External’ filter, which is reflected in the Overview tab and Crawl Overview Report. Thanks to Aleyda for the nudge on that one!
- Tabs can be re-ordered more efficiently by dragging, or via a new ‘configure tabs’ menu available via a right-click on a tab or the tab down arrow.
- The main scheduling UI has been updated with details of task name, next run, interval and has improved validation for potential issues that might stop it launching.
- There’s a new ‘Save & Open’ option for exports, which works for all formats.
- GA & GSC configs now have date pre-sets (last week, last month etc) which can be saved as part of the configuration and supplied in scheduled crawls.
- The PSI integration now has Interaction to Next Paint (INP) and Time to First Byte (TTFB) metrics available.
- The ‘Ignore Non-Indexable URLs for On-Page Filters’ configuration has been updated to ‘Ignore Non-Indexable URLs for Issues‘ and will by default, not flag non-indexable URLs for checks related to issues across a wider range of tabs and filters as detailed in-app and in the user guide.
- The hreflang tag limit has been increased from 200 to 500, for websites that have
lost the plotlots of alternative localised URLs. - All new tabs, filters and issues, warnings and opportunities counts are available in the ‘Export for Data Studio’ and Data Studio Crawl Report via scheduling.
- The SEO Spider has been updated to Java 17.
- Fixed lots of small bugs that nobody wants to read about, particularly when everyone is on holiday and nobody is reading this.
We hope the new update is useful.
A big thank you goes out to our beta testers who have helped with the different language versions of our new in-app issue descriptions. In particular, MJ Cachón for translation help, a new Spanish Google Data Studio crawl template – and generally being awesome.
As always, thanks to the SEO community for your continued support, feedback and feature requests. Please let us know if you experience any issues with version 17.0 of the SEO Spider via our support.
Small Update – Version 17.1 Released 23rd August 2022
We have just released a small update to version 17.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix issue preventing scheduling working on Ubuntu.
- Fix issue preventing JavaScript crawling working on Ubuntu.
- Fix cookies issues around forms based authentication.
- Fix JavaScript crawling failing to render some pages.
- Fix crash when changing filters in the Response Codes tab.
- Fix crash crawling URLs with HTTP in the domain name.
- Fix crash selecting ‘Save & Open’.
Small Update – Version 17.2 Released 12th September 2022
We have just released a small update to version 17.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Reinstate auto scrolling behaviour at the bottom of table view, so users can see URLs appear as they are dicovered. Thanks to Pete Mindenhall, Steve Morgan and a few others that spotted it.
- Add handling for webp files in bad content filter.
- Fix regression in cookie handling not showing all cookies.
- Fix issue showing incorrect values for Total Internal/External URLs when ignoring URLs blocked by robots.txt.
- Fix issue with last mode used not being persisted after restarts.
- Fix issue with new Issues tab graphs not updating during a crawl.
- Fix issue with new task dialog showing single digits for time.
- Fix issue with selected filter being lost when returning to a tab.
- Fix issue with old Response Codes 5XX export tab not working on upgrade.
- Fix issue with Spelling & Grammer crashing when used on Apple Silicon.
- Fix issue with Response Codes 4XX filtering showing 2XX responses after re-spider & reload.
- Fix issue with grabled fonts affecting users with their own version of Roboto font installed.
- Fix crash in view source panel.
- Fix crash crawling robots.txt with long Sitemap: line.
- Fix crash around detachable tabs and full screen on macOS.
- Fix crash showing ‘Visualisations > Force-Directed Crawl Diagram’.
- Fix crash removing/re-spidering URL.
- Fix crash viewing scheduling history.
Leave a Reply