
One of the most powerful features of the Screaming Frog SEO Spider is the ability to scrape whatever information you want from a website in bulk using custom extractions. I have previously written about using XPath for custom extractions, which is a great place to get started if you’re interested in learning the basics. You can also see my talk on this subject at BrightonSEO in April 2024. If you want to create advanced custom extractions, you will need to learn how to use functions.
Screaming Frog has just released version 21, which has upgraded its support from XPath 1.0 to 2.0, 3.0 and 3.1. This means we can now use advanced functions to turn those custom extractions up to 11. See below for some examples of XPath functions as well as examples of how they can be used to scrape information from sites. Hopefully, these will inspire you to create your own custom extractions to achieve some amazing analysis.
This article is a guest contribution from David Gossage, SEO Manager at Click Consult.
string-join()
What it does: This function combines multiple pieces of content that match your XPath query, separated by a specified delimiter.
Syntax:string-join([Target XPath],"[delimeter]")
Example: Extract all text from <p> tags, separated by spaces:
string-join([//p," ")
This is especially handy for messy HTML templates (looking at you, Bootstrap). Instead of dealing with fragmented data, you get a single, clean string.
distinct-values()
What it does: Removes duplicates from your extraction results, returning only unique values.
Syntax:
distinct-values([Target XPath])
Example 1: Get a list of all unique CSS classes used on a page:
distinct-values(//@class)
This will return a de-duplicated list of every class that is used on a page. When used to crawl your entire site, you can then compare your list with your CSS file to see if there are any unused styles that can be removed to make your site load faster.
Example 2: You can combine it with the count() function to identify pages with bloated HTML:
count(distinct-values(//@class))
This will count the number of unique classes which are on each page. The idea is that the more unique classes there are, the more bloated the HTML is and the greater the opportunity is to create cleaner code that loads quickly and is easier for search engines to render.
starts-with()
What it does: This little gem was actually supported by the SEO Spider before the latest release, but I’ve only just discovered it. It filters the results to include those that begin with a certain character or string.
Syntax:
starts-with([Target XPath] 'lookup string’)]
Example: A really powerful use for this is to extract all relative URLS, meaning that you can get a list of all internal links from every page as follows:
//a[starts-with(@href, '/')]/@href
This will extract every URL which begins with / from every link on the page so you can audit your internal linking strategies or navigation audits.
ends-with()
What it does: This function works in the same way, but to search for the string at the end of the attribute.
Syntax:
ends-with([Target XPath] 'lookup string’)]
Example: This can be used to find all links to certain file types, such as PDF documents:
//a[ends-with(@href, '.pdf')]/@href
matches()
What it does: This enables you to combine XPath with Regex to turbo-charge your custom extractions. The beauty of this rule is that you can use several conditions at once to extract based on a range of criteria.
Syntax:
matches([Target XPath], '[regex rule]')]
Example 1: Extract links to image files:
//a[matches(@href, '\.(jpg|png|gif)$')]/@href
This will return the URLs of any links that contain jpg, png or gif. Since links to images do not generally add value, this can help to find those dead ends to your navigation.
Example 2: You can use this to identify any links containing UTM parameters, which can play havoc with your analytics tracking:
//a[matches(@href, 'utm_')]/@href
exists()
What it does: Check if a certain piece of HTML actually exists on a page, as follows:
Syntax:
exists([Target XPath])
Example: This can be used to identify where important HTML snippets are missing, such as meta descriptions:
exists(//meta[@name='description'])
The output will be a boolean value of either “true” if the element exists and “false” if not.
format-dateTime()
What it does: You can format your publish dates in a way that is easier to organise by date with a great deal of ease. This is dependent on your articles having an attribute that contains the date and time in a format that the XPath can read.
Syntax:format-dateTime([Target XPath], '[Y0001]-[M01]-[D01]')
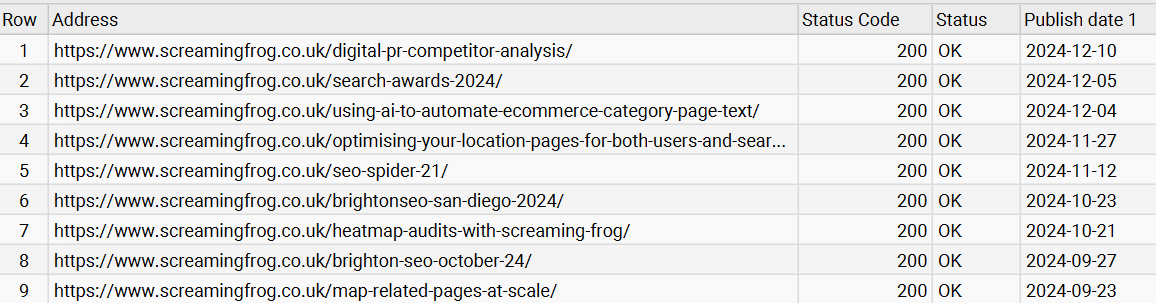
Example: The following example will organise dates into YYYY-MM-DD format:
format-dateTime(//time/@datetime, '[Y0001]-[M01]-[D01]')
Alternatively, you can get the dates from the Open graph data as follows:
format-dateTime(//meta[@property="article:published_time"]/@content, '[Y0001]-[M01]-[D01]')
The result can be seen as follows:
if()
What it does: This powerful function will return the value of an XPath only if certain conditions are met.
Syntax:
if([conditional XPath]) then [Target XPath] else ''
Example: Check the canonical URLs of pages with noindex tags using the following XPath rule:
if(contains(//meta[@name='robots']/@content, 'noindex')) then //link[@rel='canonical']/@href else 'Not noindexed'
This concept can be used for a wide range of different applications, from inconsistent canonical tags, missing alt descriptions, nofollow links to social profiles and more.
You can ramp this up by using comparison operators such as < or > to filter down your results. Let’s look at the following example, which counts how many <p> tags are in your article to identify thin content and then returns that content for quick analysis:
if(count(//p) < 4) then string-join(//p, ' ') else ''
tokenize()
What it does: This function splits the extracted value by a delimiter, similar to how the SPLIT() function works in Google Sheets. It can take a few goes to get it right so bear with us.
Syntax:
[Target XPath] ! tokenize(., '[delimiter]')
Example: Check the canonical URLs of pages with noindex tags using the following XPath rule:
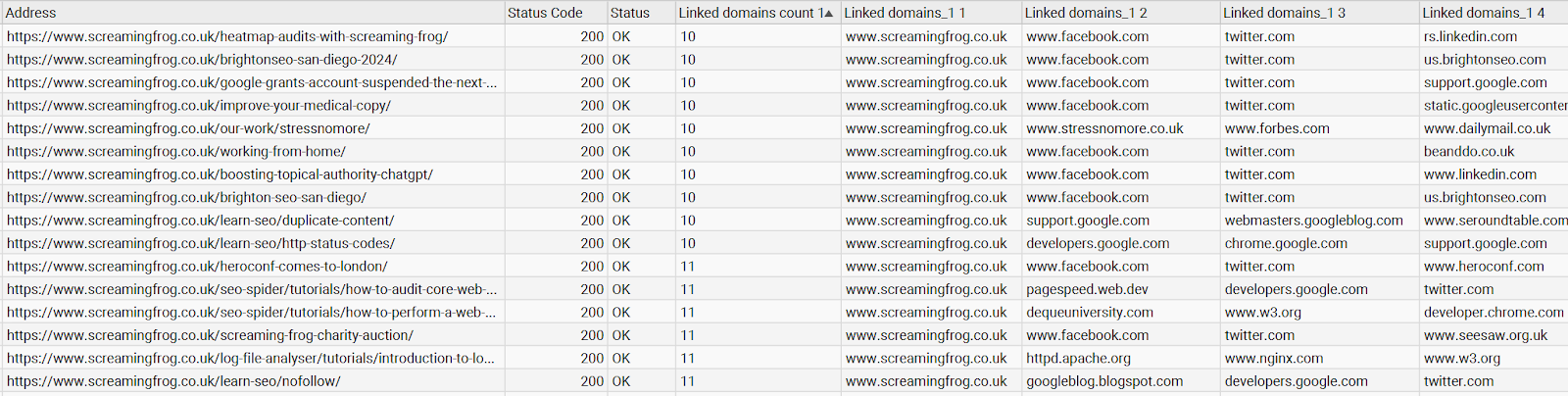
//a[contains(@href,"http")]/@href ! tokenize(., '/')[3]
So the first part is the target XPath you’re looking to extract, in this case all links which contain “http” in the URL. The second part splits it out every time a slash appears. I’ve put [3] at the end to only return the result after the third instance of extracted content (ie. the domain name).
For this example, I’ve also added the distinct-values() function to remove duplicates from the list for the following results:
One more example…
The Screaming Frog team has previously written about scraping social meta tags. However, this method is quite manual to set up and will result in a separate column for each tag resulting in extra work to combine them into a usable format. However, you can combine some of the rules above, along with the concat() function to extract all your Open graph tags into a single cell:
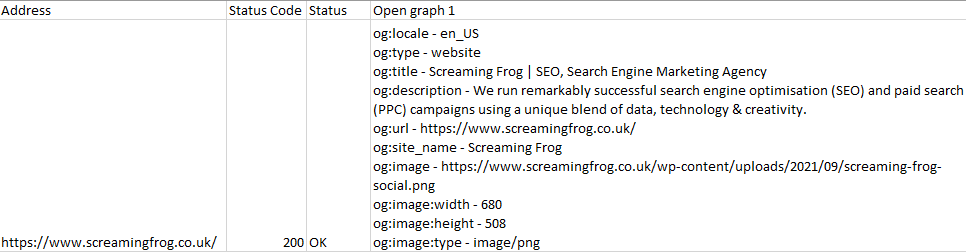
string-join(//meta[starts-with(@property, 'og:')]/concat(@property, " - ", @content), codepoints-to-string(10))
Ok, this is a difficult one to follow but it looks for all meta tags where “property” begins with “og:”, which is then concatenated with the value for “content” in the same tag. Once it’s found all these tags, it then joins them with the string-join() function, delimited by line breaks (exhale).
When running your extraction, it will look like its all joined on a single row. However, if you copy or export the contents elsewhere it should look nice and tidy like in the CSV export shown below:
Conclusion
Many thanks to Chris and Liam (literal geniuses) from the Screaming Frog team with help on this, I wouldn’t have been able to write this without you. We’d love to hear how you’re using these advanced functions as part of your SEO strategy. If you have a killer XPath, let us know!

Leave a Reply