
We’re delighted to announce Screaming Frog SEO Spider version 20.0, codenamed internally as ‘cracker’.
It’s incredible to think this is now our 20th major release of the software, after it started as a side project in a bedroom many years ago.
Now is not the time for reflection though, as this latest release contains cool new features from feedback from all of you in the SEO community.
So, lets take a look at what’s new.
1) Custom JavaScript Snippets
You’re now able to execute custom JavaScript while crawling. This means you’re able to manipulate pages or extract data, as well as communicate with APIs such as OpenAI’s ChatGPT, local LLMs, or other libraries.
Go to ‘Config > Custom > Custom JavaScript’ and click ‘Add’ to set up your own custom JS snippet, or ‘Add from Library’ to select one of the preset snippets.
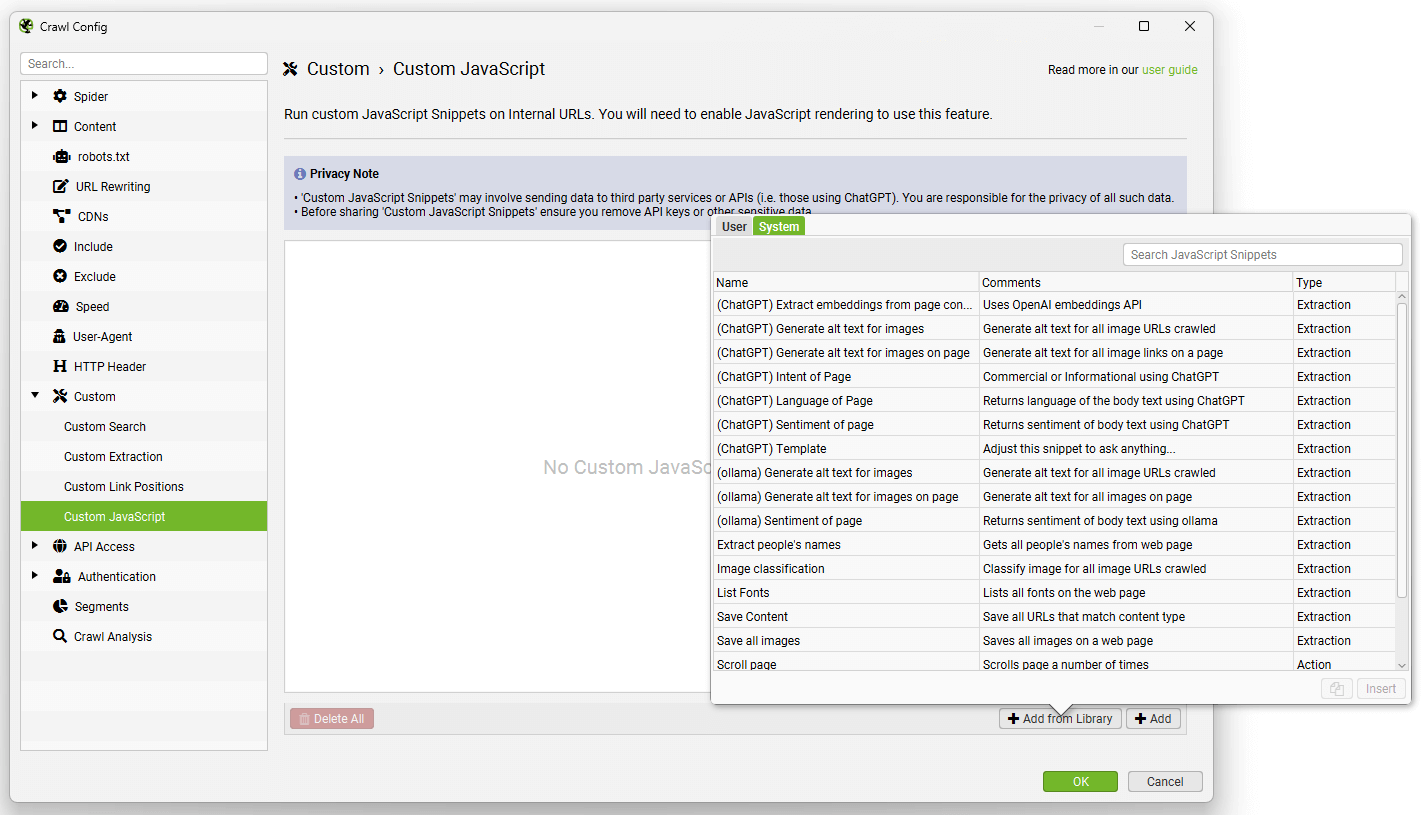
You will also need to set JavaScript rendering mode (‘Config > Spider > Rendering’) before crawling, and the results will be displayed in the new Custom JavaScript tab.
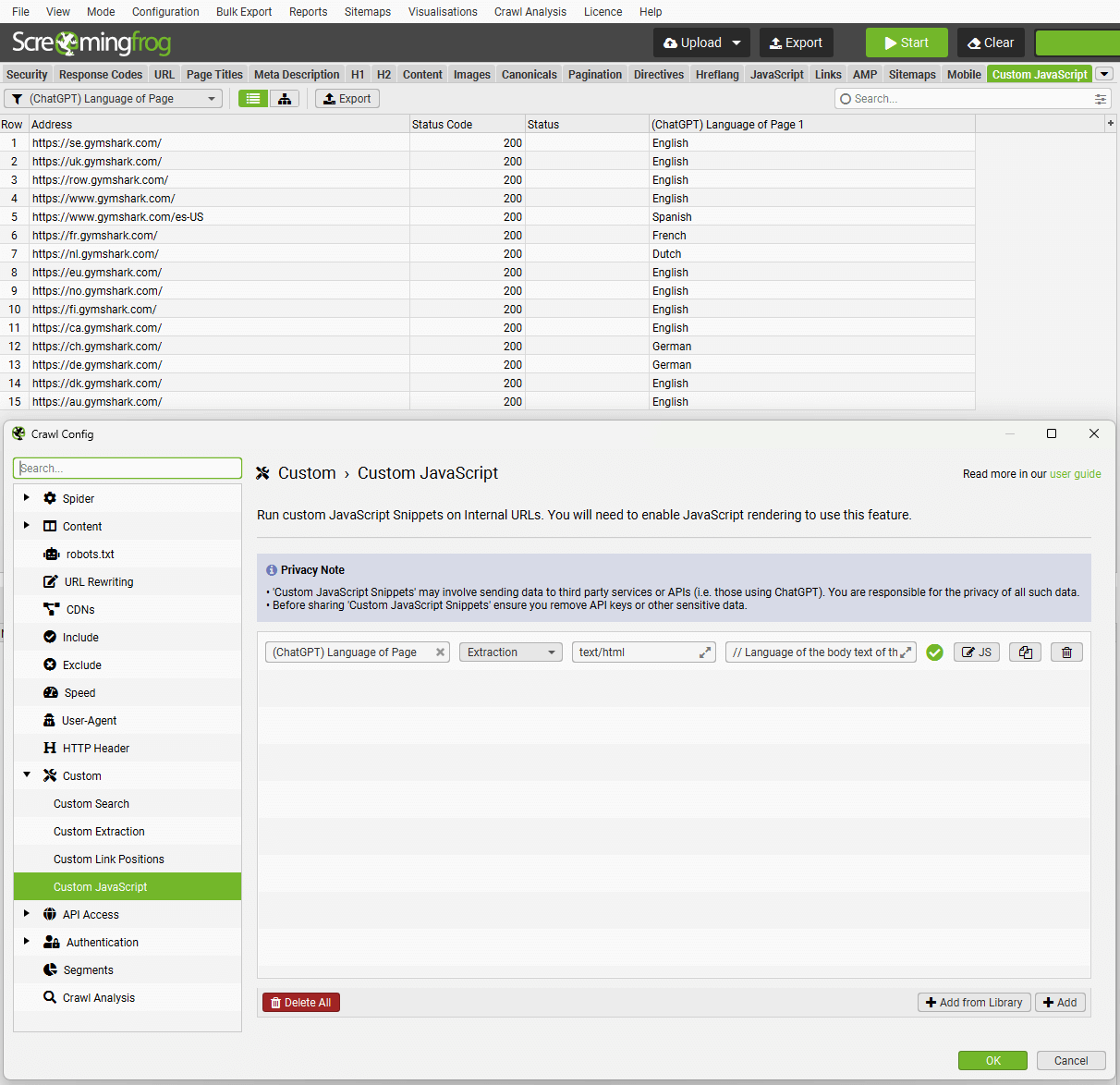
In the example above, it shows the language of the body text of a websites regional pages to identify any potential mismatches.
The library includes example snippets to perform various actions to act as inspiration of how the feature can be used, such as –
- Using AI to generate alt text for images.
- Triggering mouseover events.
- Scrolling a page (to crawl some infinite scroll set ups).
- Downloading and saving various content locally (like images, or PDFs etc).
- Sentiment, intent or language analysis of page content.
- Connecting to SEO tool APIs that are not already integrated, such as Sistrix.
- Extracting embeddings from page content.
And much more.
While it helps to know how to write JavaScript, it’s not a requirement to use the feature or to create your own snippets. You can adjust our templated snippets by following the comments in them.
Please read our documentation on the new custom JavaScript feature to help set up snippets.
Crawl with ChatGPT
You can select the ‘(ChatGPT) Template’ snippet, open it up in the JS editor, add your OpenAI API key, and adjust the prompt to query anything you like against a page while crawling.
At the top of each template, there is a comment which explains how to adjust the snippet. You’re able to test it’s working as expected in the right-hand JS editor dialog pre-crawling.
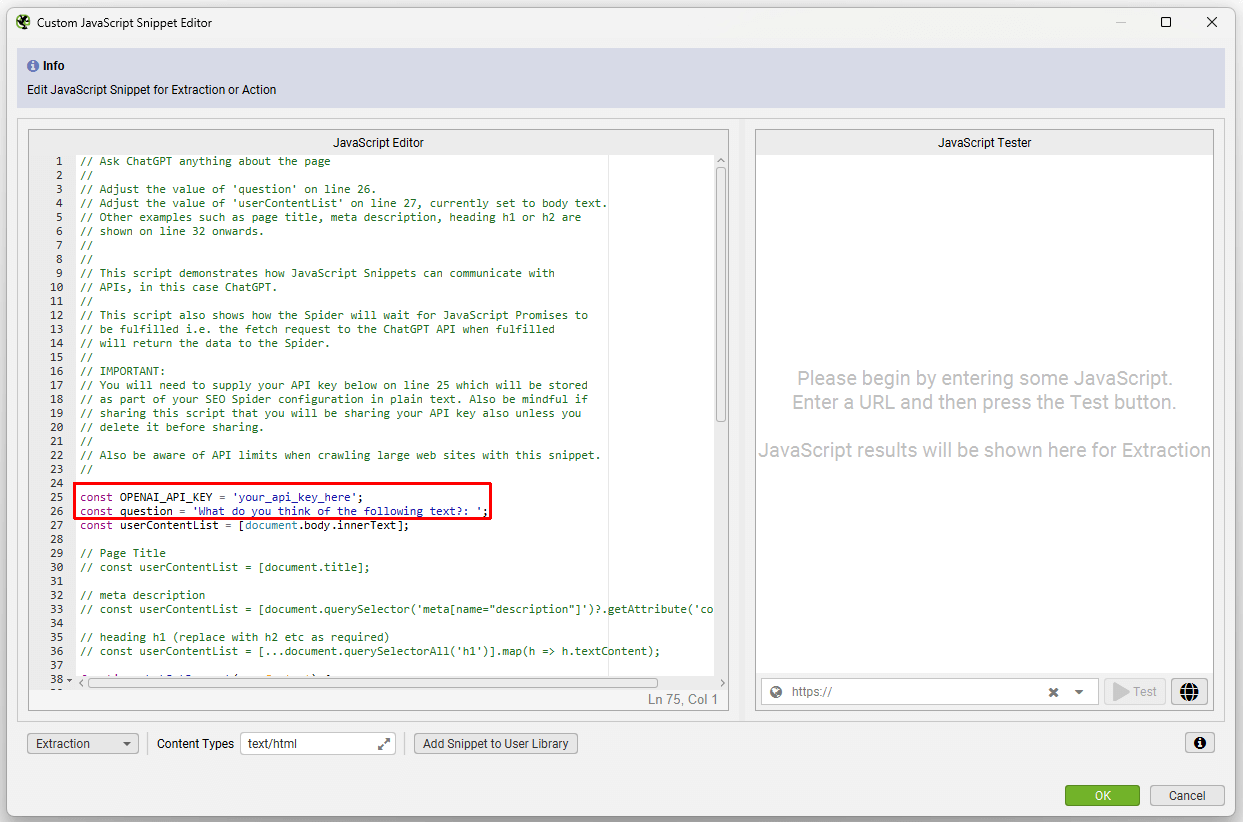
You can also adjust the OpenAI model used, specific content analysed and more. This can help perform fairly low-level tasks like generating image alt text on the fly for images for example.

Or perhaps coming up with new meta descriptions for inspiration.

Or write a rap about your page.

Possibly too far.
There’s also an example snippet which demonstrates how to use LLaVa (Large Language and Vision Assistant) running locally using Ollama as an alternative.
Obviously LLMs are not suited to all tasks, but we’re interested in seeing how they are used by the community to improve upon ways of working. Many of us collectively sigh at some of the ways AI is misused, so we hope the new features are used responsibly and for genuine ‘value-add’ use cases.
Please read our new tutorial on ‘How To Crawl With ChatGPT‘ to set this up.
Share Your Snippets
You can set up your own snippets, which will be saved in your own user library, and then export/import the library as JSON to share with colleagues and friends.

Don’t forget to remove any sensitive data, such as your API key before sharing though!
Unfortunately we are not able to provide support for writing and debugging your own custom JavaScript for obvious reasons. However, we hope the community will be able to support each other in sharing useful snippets.
We’re also happy to include any unique and useful snippets as presets in the library if you’d like to share them with us via support.
2) Mobile Usability
You are now able to audit mobile usability at scale via the Lighthouse integration.
There’s a new Mobile tab with filters for common mobile usability issues such as viewport not set, tap target size, content not sized correctly, illegible font sizes and more.

This can be connected via ‘Config > API Access > PSI’, where you can select to connect to the PSI API and collect data off box.
Or as an alternative, you can now select the source as ‘Local’ and run Lighthouse in Chrome locally. More on this later.

Granular details of mobile usability issues can be viewed in the lower ‘Lighthouse Details’ tab.

Bulk exports of mobile issues including granular details from Lighthouse are available under the ‘Reports > Mobile’ menu.
3) N-grams Analysis
You can now analyse phrase frequency using n-gram analysis across pages of a crawl, or aggregated across a selection of pages of a website.
To enable this functionality, ‘Store HTML / Store Rendered HTML’ needs to be enabled under ‘Config > Spider > Extraction’. The N-grams can then be viewed in the lower N-grams tab.

While keywords are less trendy today, having the words you want to rank on the page typically helps in SEO.
This analysis can help improve on-page alignment, identify gaps in keywords and also provide a new way to identify internal link opportunities.
New Approach to Identifying Internal Linking Opportunities
The N-grams feature provides an alternative to using Custom Search to find unlinked keywords for internal linking.
Using n-grams you’re able to highlight a section of a website and filter for keywords in ‘Body Text (Unlinked)’ to identify link opportunities.
Click on the image to see a larger version.
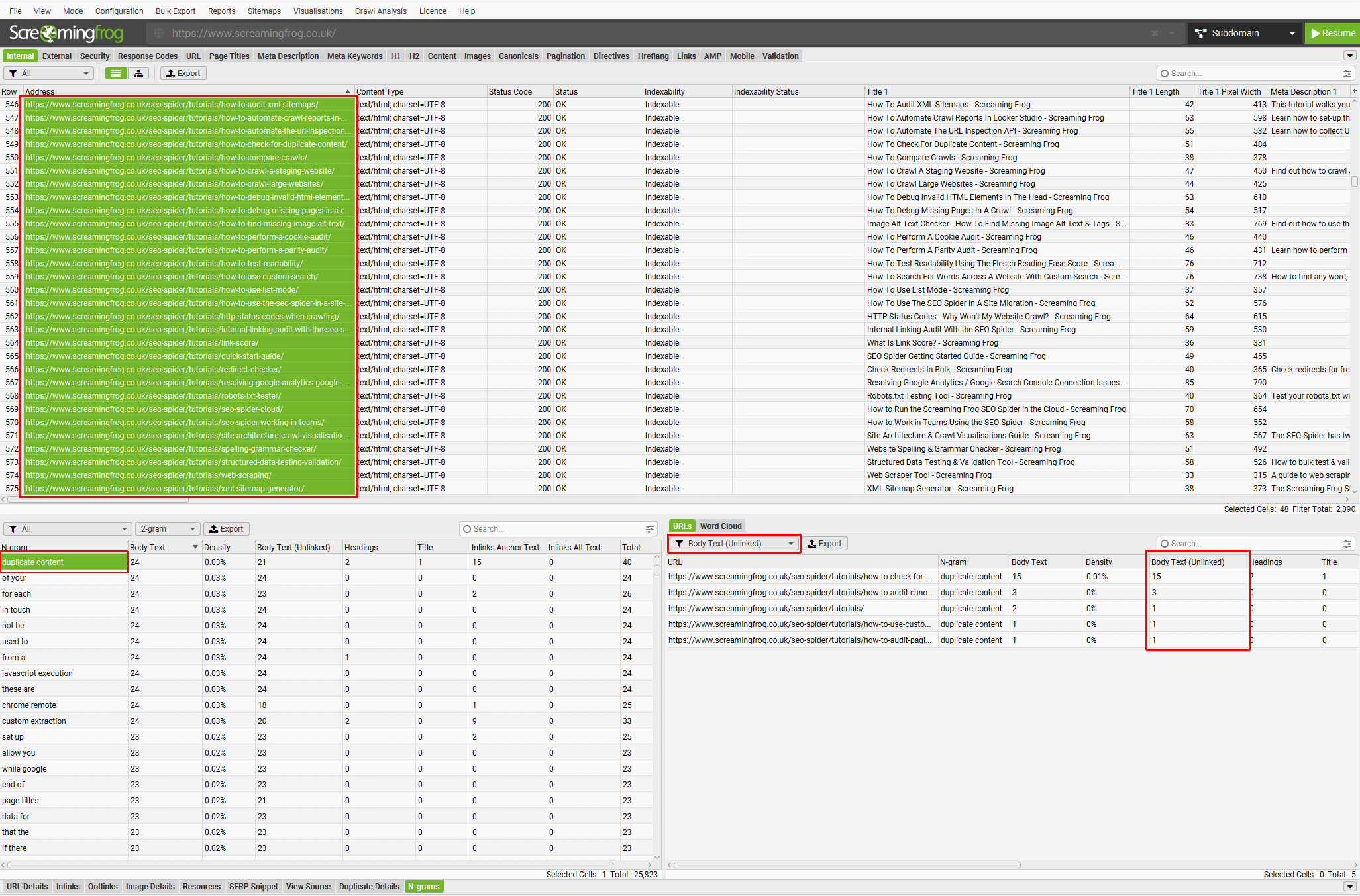
In the example above, our tutorial pages have been highlighted to search for the 2-gram ‘duplicate content’.
The right-hand side filter has been set to ‘Body Text (Unlinked)’ and the column of the same name shows the number of instances unlinked on different tutorial pages that we might want to link to our appropriate guide on how to check for duplicate content.
Multiple n-grams can be selected at a time and exported in bulk via the various options.
This feature surprised us a little during development at how powerful it could be having your own internal database of keywords to query. So we’re looking forward to seeing how it’s used in practice and could be extended.
4) Aggregated Anchor Text
The ‘Inlinks’ and ‘Outlinks’ tab have new filters for ‘Anchors’ that show an aggregated view of anchor text to a URL or selection of URLs.

We know the text used in links is an important signal, and this makes auditing internal linking much easier.
You can also filter out self-referencing and nofollow links to reduce noise (for both anchors, and links).

And click on the anchor text to see exactly what pages it’s on, with the usual link details.

This update should aid internal anchor text analysis and linking, as well as identifying non-descriptive anchor text on internal links.
5) Local Lighthouse Integration
It’s now possible run Lighthouse locally while crawling to fetch PageSpeed data, as well as Mobile as outlined above. Just select the source as ‘Local’ via ‘Config > API Access > PSI’.

You can still connect via the PSI API to gather data externally, which can include CrUX ‘field’ data. Or, you can select to run Lighthouse locally which won’t include CrUX data, but is helpful when a site is in staging and requires authentication for access, or you wish to check a large number of URLs.
This new option provides more flexibility for different use cases, and also different machine specs – as Lighthouse can be intensive to run locally at scale and this might not be the best fit for some users around the world.
6) Carbon Footprint & Rating
Like Log File Analyser version 6.0, the SEO Spider will now automatically calculate carbon emissions for each page using CO2.js library.
Alongside the CO2 calculation there is a carbon rating for each URL, and new ‘High Carbon Rating’ opportunity under the ‘Validation’ tab.

The Sustainable Web Design Model is used for calculating emissions, which considers datacentres, network transfer and device usage in calculations. The ratings are based upon their proposed digital carbon ratings.
These metrics can be used as a benchmark, as well as a catalyst to contribute to a more sustainable web. Thank you to Stu Davies of Creative Bloom for encouraging this integration.
Other Updates
Version 20.0 also includes a number of smaller updates and bug fixes.
- Google Rich Result validation errors have been split out from Schema.org in our structured data validation. There are new filters for rich result validation errors, rich result warnings and parse errors, as well as new columns to show counts, and the rich result features triggered.
- Internal and External filters have been updated to include new file types, such as Media, Fonts and XML.
- Links to media files (in video and audio tags) or mobile alternate URLs can be selected via ‘Config > Spider > Crawl’.
- There’s a new ‘Enable Website Archive’ option via ‘Config > Spider > Rendering > JS’, which allows you to download all files while crawling a website. This can be exported via ‘Bulk Export > Web > Archived Website’.
- Viewport and rendered page screenshot sizes are now entirely configurable via ‘Config > Spider > Rendering > JS’.
- APIs can ‘Auto Connect on Start’ via a new option.
- There’s a new ‘Resource Over 15mb‘ filter and issue in the Validation Tab.
- Visible page text can be exported via the new ‘Bulk Export > Web > All Page Text’ export.
- The ‘PageSpeed Details’ tab has been renamed to ‘Lighthouse Details’ to include data for both page speed, and now mobile.
- There’s a new ‘Assume Pages are HTML’ option under ‘Config > Spider > Advanced’, for pages that do not declare a content-type.
- Lots of (not remotely tedious) Google rich result validation updates.
- The SEO Spider has been updated to Java 21 Adoptium.
That’s everything for version 20.0!
Thanks to everyone for their continued support, feature requests and feedback. Please let us know if you experience any issues with this latest update via our support.

Leave a Reply